

[caption class="snax-figure" align="aligncenter" width="1140"][/caption]
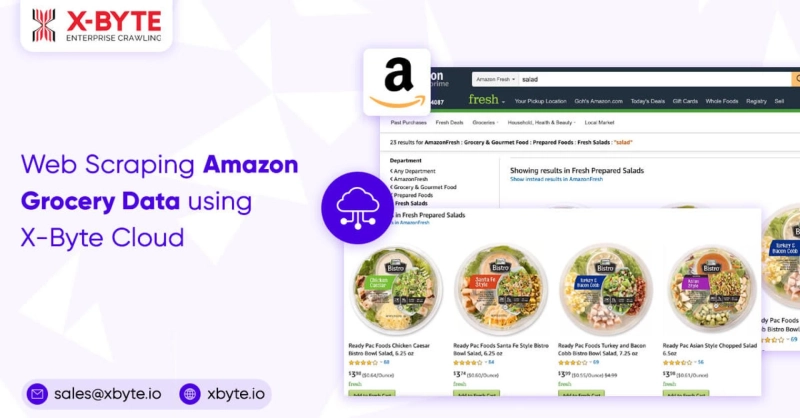
Having over 350 million products across product types and activities, Amazon acquired 45% of the US e-commerce market share in 2020. It is one of the world's largest online marketplaces. By using the Amazon scraping tool to scrape grocery delivery information will assist you to easily study your competition, keeping a record of important product information like prices and ratings, and spot emerging market trends.
[caption class="snax-figure" align="aligncenter" width="1140"][/caption]
Below are the Steps for Scraping Amazon Grocery Delivery Data
Creating an account on X-byte Cloud.Selecting the Amazon scraping tool for instance Amazon search results Scraper.Enter the list of input URLs.Execute the crawler, and download the required data.X-Byte Cloud's pre-built scrapers allow you to extract publicly available data from Google, retail websites, social media, financial websites, and more. X-Byte’s cloud-based web crawlers make web scraping simple. Furthermore, no extra software is required to organize a scraping job. You can use your browser to access the scraper at any moment, enter the required input URLs, and the data will be delivered to you.
Data Fields Scraped from Amazon Grocery Delivery Data
Using Amazon search result scraper, we can extract the below-given data fields:
Product nameCategoryPriceReviewsRatingsDescriptionsASINSeller informationHow to Scrape Amazon Grocery Delivery Data?
The Amazon Search Results Scraper from X-Byte Cloud is simple to use and allows you to safeguard data in the most efficient way possible. The required data and information can be collected from Amazon's food search results page.
Step 1: Creating an X-Byte cloud Account for using Amazon Scraping Tool
Sign up on X-Byte Cloud by signing up using an email address and other details. https://www.xbyte.io/amazon-product-search.php
Before subscribing to X-Byte Cloud, you can try scraping 20-25 pages for free. A thorough explanation of how to execute the Amazon Search Results Scraper, which is available on X-Byte Cloud, can be seen below.
Step 2: Add the Amazon Search Result Crawler to Account and Provide with Necessary Requirements.
After making an account on X-Byte Cloud, go to the Crawlers tab and add the Amazon Search Results Scraper.
After that, select ‘Add this crawler to my account.' The main basic page, as shown under the ‘Input' tab, has all data fields:
1. Crawler Name:
Providing a name to your crawlers may help you distinguish between scraping operations. Fill in the chosen name in the input field and save your changes at the end of the screen by clicking the ‘Save Settings' button.
2. Domain
You may extract comprehensive product information from categories or search engine results on Amazon US, Amazon Canada, and Amazon UK with X-Byte’s Amazon Search Result Scraper. Simply type in the domain you want to scrape into the input field and the scraper will handle the rest.
3. Search Result URLs
Then, throughout this data field, enter your target URLs. We recommend utilizing no more than three input URLs if you're on the free plan. If you currently have an X-Byte Cloud subscription, you can add an unlimited number of URLs for the Amazon Search Results Scraper to extract the data.
If you want to scrape more than one URL, enter them one after the other, separated by a new line (press Enter key). The URLs for the search results can be obtained from Amazon's website in the following way:
Select an Amazon Fresh category now. You can also use filters to narrow down your search results if necessary. Then, the Search Results URLs data field will work as follow:
4. Keywords
Users must enter a list of keywords that they'd like to scrape Amazon grocery data for in this area. Keywords such as 'organic apples,' 'fresh apples,' and 'fresh Honeycrisp apples,' can be used.
If you're not sure what keywords to use, you can use the desired search results URL as input instead.
5. Brand Name
Thousands of brands can be found on Amazon's marketplace. Scraping can be accelerated by including the names of your competitors' brands.
6. Number of Pages to Scrape
On Amazon, you can choose the amount of search results pages to scrape. You can select from the following options:
You can enter the required number of documents in the ‘Custom number of pages' data section below if you have special needs.
Step 3: Running the Amazon Search Results Scraper
After you've filled in all of the information, click 'Save Settings' to save your changes.
To get started, go to the top of the page and click on ‘Gather Data.'
Under the tasks tab, you can check the status of the Amazon scraping program. The status of the scraper may be found there.
If the status is set to ‘Running,' your data is being collected.
If the status is ‘Finished,' it means the crawler has completed the task.
Step 4: Download the Scraped Information
Finally, select ‘View Data' to see the collected data, or ‘Download' to save the results to your computer in Excel, CSV, or JSON format.
The below image shows the scraped grocery information in CSV format.
Features of the X-Byte Cloud Amazon Search Results Scraper
Scheduling the Scraping ProcessYou can schedule your data crawling using X-Byte Cloud at your convenience.
Generating API Key:API keys allow the user to create the crawlers and improve the efficiency of the operation. This key can be found on the Integrations tab.
Immediate data Delivery to Dropbox account – You can upload all of the obtained data to a Dropbox account if you pay for an X-Byte cloud subscription. This way, anyone can read the system whenever and anywhere they choose. This feature can be found under the Integrations tab.Gathering Solutions to Scrape Amazon Data
Of course, Amazon has one of the largest publicly accessible data collections. Customer preferences, market trends, product reviews, ratings, product descriptions, and other information can all be included in the data. Web scraping is a fantastic solution because it eliminates the need to manually search through all of Amazon's data. X-Byte Cloud ensures that you do have instant access to this structured and reliable data.
While you concentrate on other key business activities, then Amazon Search Results Crawler may retrieve crucial grocery delivery information and more. Scraping for grocery data with the Amazon Search Results Crawler on X-Byte Cloud is only the effective way to extract the required information.
Looking for Scraping Amazon Grocery Delivery Data, Contact X-Byte Enterprise Crawling Now!!
For more visit: https://www.xbyte.io/web-scraping-amazon-grocery-data-using-x-byte-cloud.php