Retrieval-Augmented Generation (RAG) has revolutionized the field of Natural Language Processing (NLP) by combining the strengths of retrieval-based and generation-based approaches. However, as NLP tasks grow in scale and complexity, RAG models face significant challenges in efficiently retrieving relevant information. Vector databases have emerged as a crucial component in optimizing RAG for large-scale NLP tasks, enabling fast and accurate retrieval of semantic information.
Understanding RAG:
Retrieval-Augmented Generation (RAG) is a novel approach in Natural Language Processing (NLP) that combines the strengths of retrieval-based and generation-based methods. RAG models consist of two primary components: a retriever and a generator.
The retriever is responsible for selecting a set of relevant documents or passages from a large corpus, based on the input prompt or query. The generator then uses these retrieved documents to generate a response or answer.
Compared to conventional generation-based methods, RAG models have demonstrated notable gains, especially in tasks like dialogue production, text summarization, and question answering. RAG models can provide more accurate and informative replies, lower the chance of hallucinations, and enhance overall coherence by utilizing the recovered texts.
Instead than depending just on the few information in the input prompt, RAG\'s primary benefit is its capacity to leverage the enormous volumes of preexisting knowledge found in sizable corpora. Because of this, RAG models may produce more thorough and contextually appropriate replies, which makes them a desirable option for a variety of NLP applications.
Role of Vector Databases in RAG
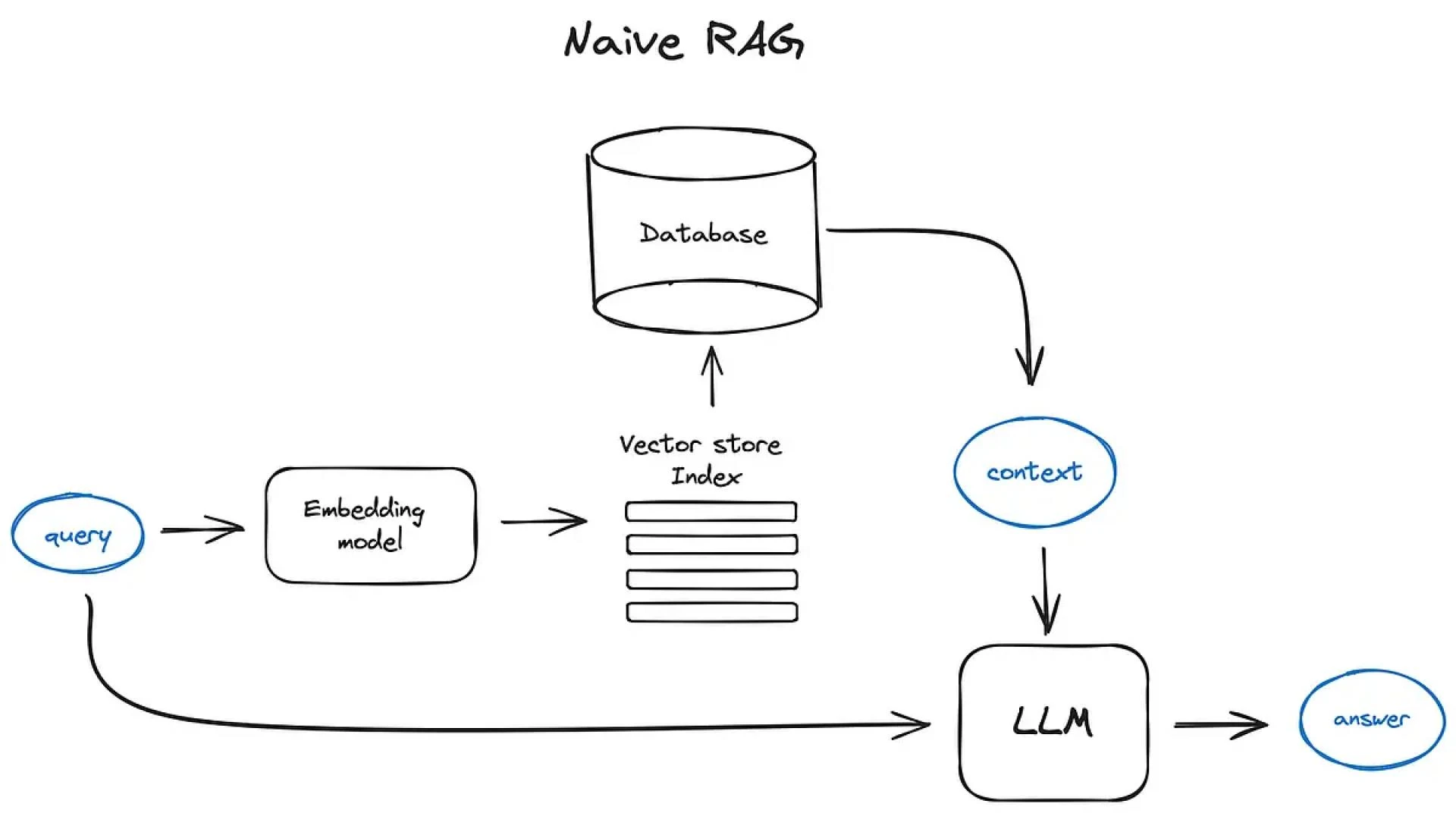
Vector databases play a crucial role in optimizing the performance of Retrieval-Augmented Generation (RAG) models, particularly in large-scale Natural Language Processing (NLP) tasks. The primary function of a vector database is to efficiently store and query dense vector representations of documents or passages in a corpus. In the context of RAG, vector databases enable fast and accurate retrieval of semantic information, which is essential for generating high-quality responses.
By indexing vector representations of documents, vector databases allow RAG models to quickly identify and retrieve the most relevant documents or passages from a massive corpus, often containing millions or even billions of documents.
This is achieved through approximate nearest neighbor search algorithms, which enable the vector database to return a set of documents that are semantically closest to the input query.
How Vector Databases optimize RAG
Vector databases play a vital role in optimizing the performance of Retrieval-Augmented Generation (RAG) models by efficiently storing and querying dense vector representations of documents or passages in a corpus. One of the primary ways vector databases optimize RAG is by enabling fast and accurate retrieval of semantic information. This is achieved through approximate nearest neighbor search algorithms, which allow the vector database to return a set of documents that are semantically closest to the input query.
I believe that the use of vector databases in RAG models significantly reduces the computational overhead associated with traditional retrieval methods, such as keyword-based search or brute-force similarity calculations. By indexing vector representations of documents, vector databases enable RAG models to quickly identify and retrieve the most relevant documents or passages, even in massive corpora.
Furthermore, vector databases can be easily scaled to handle large and complex NLP tasks, making them an essential component in many modern NLP applications. Overall, the integration of vector databases in RAG models has revolutionized the field of NLP, enabling the development of more efficient and effective language models.
Benefits of using Vector Databases in RAG
The integration of vector databases in Retrieval-Augmented Generation (RAG) models offers several benefits. Firstly, vector databases enable fast and accurate retrieval of semantic information, reducing the computational overhead associated with traditional retrieval methods. This leads to improved response times and enhanced user experience. I think that vector databases also enable RAG models to handle large and complex NLP tasks, making them scalable and efficient. Additionally, vector databases allow RAG models to capture subtle semantic relationships between documents, resulting in more accurate and informative responses.
Furthermore, vector databases can be easily updated and expanded, making them ideal for dynamic and constantly evolving language models. Overall, the use of vector databases in RAG models has improved the performance, efficiency, and accuracy of language generation tasks, making them an essential component in many modern NLP applications.
Conclusion
In conclusion, the discipline of NLP has seen a revolution thanks to the incorporation of vector datasets into RAG models. Language generation activities have become more accurate, efficient, and perform better because to vector databases, which allow for the quick and accurate retrieval of semantic information.
The emergence of inventive platforms such as Vectorize.io, offering a scalable and effective vector database solution, has made it simple for developers to construct and implement RAG models capable of managing intricate and sizable NLP jobs. The importance of vector databases in RAG models is anticipated to increase as NLP continues to develop.





Sign in to leave a comment.