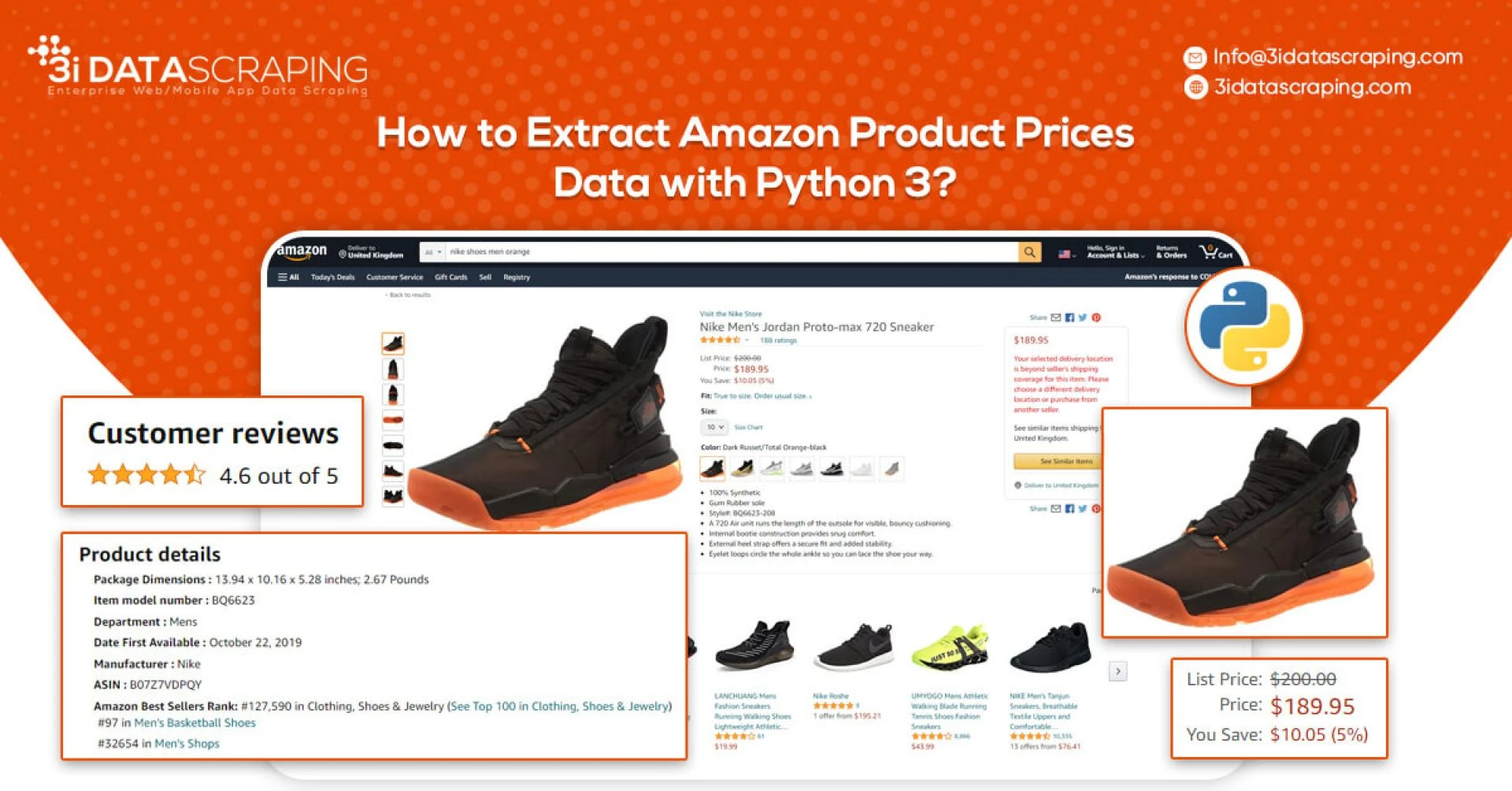
How To Extract Amazon Product Data From Amazon Product Pages?
Markup all data fields to be extracted using SelectorlibThen copy as well as run the given codeSetting Up Your Computer For Amazon Scraping
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages For Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
pip3 install requests selectorlibExtract Product Data From Amazon Product Pages
An Amazon product pages extractor will extract the following data from product pages.
Product NamePricingShort DescriptionComplete Product DescriptionRatingsImages URLsTotal ReviewsOptional ASINsLink to Review PagesSales RankingMarkup Data Fields With Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
name:
css: ‘#productTitle’type: Textprice:css: ‘#price_inside_buybox’type: Textshort_description:css: ‘#featurebullets_feature_div’type: Textimages:css: ‘.imgTagWrapper img’type: Attributeattribute: data-a-dynamic-imagerating:css: span.arp-rating-out-of-texttype: Textnumber_of_reviews:css: ‘a.a-link-normal h2’type: Textvariants:css: ‘form.a-section li’multiple: truetype: Textchildren:name:css: “”type: Attributeattribute: titleasin:css: “”type: Attributeattribute: data-defaultasinproduct_description:css: ‘#productDescription’type: Textsales_rank:css: ‘li#SalesRank’type: Textlink_to_all_reviews:css: ‘div.card-padding a.a-link-emphasis’type: Link
The markup will look like this:
Selectorlib is the combination of different tools for the developers, who make marking up as well as scraping data from pages easier. The Chrome Extension of Selectorlib helps you mark the data, which you require to scrape and create the XPaths or CSS Selectors required to scrape the data and previews about how that data will look like.
Amazon Scraping Code
Make a folder named amazon-scraper as well as paste the selectorlib yaml template file like selectors.yml
Let’s make a file named amazon.py as well as paste the code given below in it. It includes:
Read the listing of Amazon Product URLs from the file named urls.txtExtract the DataSave Data in the JSON Formatfrom selectorlib import extractorimport requestsimport jsonfrom time import sleep# Create an Extractor by reading from the YAML filee = Extractor.from_yaml_file(‘selectors.yml’)def scrape(url):headers = {‘authority’: ‘www.amazon.com’,‘pragma’: ‘no-cache’,‘cache-control’: ‘no-cache’,‘dnt’: ‘1’,‘upgrade-insecure-requests’: ‘1’,‘user-agent’: ‘Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36’,‘accept’:‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9’,‘sec-fetch-site’: ‘none’,‘sec-fetch-mode’: ‘navigate’,‘sec-fetch-dest’: ‘document’,‘accept-language’: ‘en-GB,en-US;q=0.9,en;q=0.8’,}# Download the page using requestsprint(“Downloading %s”%url)r = requests.get(url, headers=headers)# Simple check to check if page was blocked (Usually 503)if r.status_code > 500:if “To discuss automated access to Amazon data please contact” in r.text:print(“Page %s was blocked by Amazon. Please try using better proxiesn”%url)else:print(“Page %s must have been blocked by Amazon as the status code was %d”%(url,r.status_code))return None# Pass the HTML of the page and createreturn e.extract(r.text)# product_data = []with open(“urls.txt”,’r’) as urllist, open(‘output.jsonl’,’w’) as outfile:for url in urllist.readlines():data = scrape(url)if data:json.dump(data,outfile)outfile.write(“n”)# sleep(5)Run The Amazon Product Pages Scraper
Get a complete code from the link Github –
https://www.3idatascraping.com/contact-us/
You may start the scraper through typing this command:
python3 amazon.pyWhen scraping gets completed, then you can see the file named output.jsonl having the data. Let’s see the example of it:
https://www.amazon.com/HP-Computer-Quard-Core-Bluetooth-Accessories/dp/B085383P7M/
“name”: “2020 HP 15.6” Laptop Computer, 10th Gen Intel Quard-Core i7 1065G7 up to 3.9GHz, 16GB DDR4 RAM, 512GB PCIe SSD, 802.11ac WiFi, Bluetooth 4.2, Silver, Windows 10, YZAKKA USB External DVD + Accessories”,“price”: “$959.00”,“short_description”: “Powered by latest 10th Gen Intel Core i7-1065G7 Processor @ 1.30GHz (4 Cores, 8M Cache, up to 3.90 GHz); Ultra-low-voltage platform. Quad-core, eight-way processing provides maximum high-efficiency power to go.n15.6” diagonal HD SVA BrightView micro-edge WLED-backlit, 220 nits, 45% NTSC (1366 x 768) Display; Intel Iris Plus Graphicsn16GB 2666MHz DDR4 Memory for full-power multitasking; 512GB Solid State Drive (PCI-e), Save files fast and store more data. With massive amounts of storage and advanced communication power, PCI-e SSDs are great for major gaming applications, multiple servers, daily backups, and more.nRealtek RTL8821CE 802.11b/g/n/ac (1×1) Wi-Fi and Bluetooth 4.2 Combo; 1 USB 3.1 Gen 1 Type-C (Data Transfer Only, 5 Gb/s signaling rate); 2 USB 3.1 Gen 1 Type-A (Data Transfer Only); 1 AC smart pin; 1 HDMI 1.4b; 1 headphone/microphone combonWindows 10 Home, 64-bit, English; Natural silver; YZAKKA USB External DVD drive + USB extension cord 6ft, HDMI cable 6ft and Mouse Padn› See more product details”,“images”: “{”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX425_.jpg”:[425,425],”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX466_.jpg”:[466,466],”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SY355_.jpg”:[355,355],”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX569_.jpg”:[569,569],”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SY450_.jpg”:[450,450],”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX679_.jpg”:[679,679],”https://images-na.ssl-images-amazon.com/images/I/61CBqERgZ7L._AC_SX522_.jpg”:[522,522]}”,“variants”: [ { “name”: “Click to select 4GB DDR4 RAM, 128GB PCIe SSD”, “asin”: “B01MCZ4LH1” }, { “name”: “Click to select 8GB DDR4 RAM, 256GB PCIe SSD”, “asin”: “B08537NR9D” }, { “name”: “Click to select 12GB DDR4 RAM, 512GB PCIe SSD”, “asin”: “B08537ZDYH” }, { “name”: “Click to select 16GB DDR4 RAM, 512GB PCIe SSD”, “asin”: “B085383P7M” }, { “name”: “Click to select 20GB DDR4 RAM, 1TB PCIe SSD”, “asin”: “B08537NDVZ” } ],“product_description”: “Capacity:16GB DDR4 RAM, 512GB PCIe SSDnnProcessornn Intel Core i7-1065G7 (1.3 GHz base frequency, up to 3.9 GHz with Intel Turbo Boost Technology, 8 MB cache, 4 cores)nnChipsetnn Intel Integrated SoCnnMemorynn 16GB DDR4-2666 SDRAMnnVideo graphicsnn Intel Iris Plus GraphicsnnHard drivenn 512GB PCIe NVMe M.2 SSDnnDisplaynn 15.6” diagonal HD SVA BrightView micro-edge WLED-backlit, 220 nits, 45% NTSC (1366 x 768)nnWireless connectivitynn Realtek RTL8821CE 802.11b/g/n/ac (1×1) Wi-Fi and Bluetooth 4.2 CombonnExpansion slotsnn 1 multi-format SD media card readernnExternal portsnn 1 USB 3.1 Gen 1 Type-C (Data Transfer Only, 5 Gb/s signaling rate); 2 USB 3.1 Gen 1 Type-A (Data Transfer Only); 1 AC smart pin; 1 HDMI 1.4b; 1 headphone/microphone combonnMinimum dimensions (W x D x H)nn 9.53 x 14.11 x 0.70 innnWeightnn 3.75 lbsnnPower supply typenn 45 W Smart AC power adapternnBattery typenn 3-cell, 41 Wh Li-ionnnBattery life mixed usagenn Up to 11 hours and 30 minutesnn Video Playback Battery lifenn Up to 10 hoursnnWebcamnn HP TrueVision HD Camera with integrated dual array digital microphonennAudio featuresnn Dual speakersnnOperating systemnn Windows 10 Home 64nnAccessoriesnn YZAKKA USB External DVD drive + USB extension cord 6ft, HDMI cable 6ft and Mouse Pad”,“link_to_all_reviews”: “https://www.amazon.com/HP-Computer-Quard-Core-Bluetooth-Accessories/product-reviews/B085383P7M/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews”}Scraping Amazon Products From Search Results Pages
The Amazon search results pages scraper will extract the following data from different search result pages:
Product’s NamePricingURLRatingsTotal ReviewsThe code and steps for extracting the search results is similar to a product pages scraper.
Markup Data Fields With Selectorlib
Here is a selectorlib yml file. Let’s calls that search_results.yml
products:css: ‘div[data-component-type=”s-search-result”]’xpath: nullmultiple: truetype: Textchildren:title:css: ‘h2 a.a-link-normal.a-text-normal’xpath: nulltype: Texturl:css: ‘h2 a.a-link-normal.a-text-normal’xpath: nulltype: Linkrating:css: ‘div.a-row.a-size-small span:nth-of-type(1)’xpath: nulltype: Attributeattribute: aria-labelreviews:css: ‘div.a-row.a-size-small span:nth-of-type(2)’xpath: nulltype: Attributeprice:css: ‘span.a-price:nth-of-type(1) span.a-offscreen’xpath: nulltype: TextThe Code
This code is nearly matching to the earlier scraper, excluding that we repeat through every product as well as save them like a separate line.
Let’s make a file searchresults.py as well as paste the code given in it. This is what a code does:
Open the file named search_results_urls.txt as well as read the search results pages URLsExtract the dataThen save to the JSON Line files named search_results_output.jsonlfrom selectorlib import Extractorimport requestsimport jsonfrom time import sleep# Create an Extractor by reading from the YAML filee = Extractor.from_yaml_file(‘search_results.yml’)def scrape(url):headers = {‘dnt’: ‘1’,‘upgrade-insecure-requests’: ‘1’,‘user-agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36’,‘accept’:‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9’,‘sec-fetch-site’: ‘same-origin’,‘sec-fetch-mode’: ‘navigate’,‘sec-fetch-user’: ‘?1’,‘sec-fetch-dest’: ‘document’,‘referer’: ‘https://www.amazon.com/’,‘accept-language’: ‘en-GB,en-US;q=0.9,en;q=0.8’,}# Download the page using requests print(“Downloading %s”%url)r = requests.get(url, headers=headers)# Simple check to check if page was blocked (Usually 503) if r.status_code > 500:if “To discuss automated access to Amazon data please contact” in r.text:print(“Page %s was blocked by Amazon. Please try using better proxiesn”%url)else:print(“Page %s must have been blocked by Amazon as the status code was %d”%(url,r.status_code))return None# Pass the HTML of the page and createreturn e.extract(r.text)# product_data = []with open(“search_results_urls.txt”,’r’) as urllist,open(‘search_results_output.jsonl’,’w’) as outfile:for url in urllist.read().splitlines():data = scrape(url)if data:for product in data[‘products’]:product[‘search_url’] = urlprint(“Saving Product: %s”%product[‘title’])json.dump(product,outfile)outfile.write(“n”)# sleep(5)Run An Amazon Scraper For Scraping Search Results
You can begin your scraper through typing this command:
python3 searchresults.pyWhen the scraping is completed, you need to see the file named search_results_output.jsonl with the data.
The example of it is:
https://www.amazon.com/s?k=laptops
https://www.3idatascraping.com/contact-us/
What Should You Do If You Are Blocked When Scraping Amazon?
Amazon may consider you as the “BOT” in case, you start extracting hundreds of pages by the code given here. The thing is to avoid having flagged as a BOT while extracting as well as running the problems. How to cope with such challenges?
Imitate the human behavior to the maximum
As there is no assurance that you won’t get blocked. Just follow these tips about how to evade being blocked by the Amazon:
Use Proxies As Well As Switch Them
Let us assume that we are extracting thousands of products on Amazon.com using a laptop that normally has only single IP address. Amazon would assume us as a bot because NO HUMAN visits thousands of product pages within minutes. To look like the human – make some requests to Amazon using the pool of proxies or IP Addresses. The key rule is to have only 1 IP address or proxy making not over 5 requests for Amazon in one minute. In case, you scrape around 100 pages for every minute, thenn we need around 100/5 = 20 Proxies.
Specify User Agents Of The Newest Browsers As Well As Switch Them
If you observe the code given, you would get a line in which we had set the User-Agent String for requests we are doing.
‘User-Agent’: ‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36’Like proxies, it’s good to get the pool of different User Agent Strings. So, ensure that you use user-agent strings for the popular and latest browsers as well as rotate these strings for every request you do to Amazon. It is a good idea of creating a grouping of (IP Address, User-Agent) so it looks human than the bot.
Decrease The Total ASINs Extracted Every Minute
You can also try to slow down the scrapping a bit for giving Amazon lesser chances of considering you as the bot. However, around 5 requests for every IP per minute isn’t throttling much. If you want to go quicker, add additional proxies. You can adjust the speed through decreasing or increasing the delay within the sleep functions.
Continue Retrying
Whenever you get blocked by the Amazon, ensure you retry the request. If you are looking at a code block given we have included 20 retries. Our codes retry immediately after scraping fails, you can do a better job by making the retry queues using the list, as well as retry them when all the products get scraped from the Amazon.
If you are looking to get Amazon product data and prices scraping using Python 3 then contact 3i Data Scraping!






Sign in to leave a comment.