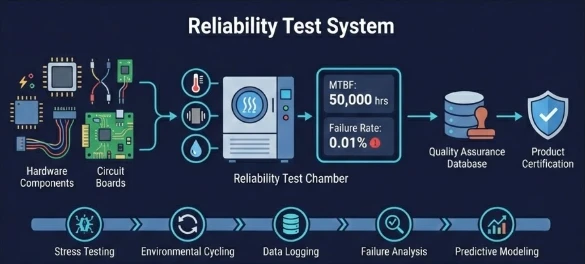
In today’s "always-on" digital economy, a single minute of downtime can cost a company thousands of dollars and irreparable brand damage. This is where a reliability test system becomes the backbone of software development.
But what does it actually take to build a system that doesn't just work, but stays working? Let’s dive into the essentials of reliability testing, from core strategies to the tools that automate the heavy lifting.
What is a Reliability Test System?
A reliability test system is a structured framework designed to evaluate how consistently a software application performs under specific conditions over a set period. Unlike standard functional testing (which asks, "Does this button work?"), reliability testing asks, "Will this button keep working after 10,000 clicks, or if the server is under a 90% load?"
Core Objectives
- Consistency: Ensuring performance doesn't degrade over time.
- Failure Discovery: Identifying "breaking points" before they reach the user.
- Stability Validation: Checking how the environment (cloud, local, or hybrid) affects the app.
- Risk Mitigation: Preventing data loss and security breaches caused by system crashes.
The 7 Pillars of Reliability Testing
To build a comprehensive reliability test system, you need to incorporate these seven types of testing:
| Test Type | Focus Area | Why It Matters |
| Load Testing | Normal expected traffic | Ensures the app handles daily users smoothly. |
| Stress Testing | Beyond normal limits | Identifies the "breaking point" of the system. |
| Volume Testing | Large data sets | Checks if the database slows down as it grows. |
| Spike Testing | Sudden traffic bursts | Essential for "flash sales" or viral events. |
| Endurance Testing | Long-term activity | Catches slow-burning issues like memory leaks. |
| Recovery Testing | Post-crash behavior | Measures how fast the system "reboots" after a failure. |
| Configuration | Hardware/OS variety | Ensures the app works on Chrome, Safari, iOS, etc. |
How to Measure Success: Key Metrics
You cannot improve what you cannot measure. A high-performing reliability test system
tracks these three critical numbers:
- Mean Time Between Failures (MTBF): The average time the system runs before an error occurs.
- Formula:
MTBF = Total uptime / Number of failures
- Failure Rate: The frequency of crashes over a specific duration.
- Mean Time to Repair (MTTR): How quickly your team (or the system itself) can fix
an issue after it’s detected.
Steps to Implement Reliability Testing
- Define Your "North Star": Set a goal, such as "99.9% uptime" (which allows for only 43 minutes of downtime per month).
- Simulate Real-World Scenarios: Don't just test "perfect" data. Use Python scripts or automated tools to simulate "messy" user behavior.
- Log Everything: Use an automated logging system to capture exactly why a failure happened.
- Iterate: Fix the bug, then run the exact same test again to ensure the "fix" didn't break something else.
Modern Tools for the Modern Dev
Manually testing for reliability is nearly impossible in the age of CI/CD. Here are the industry leaders:
- Apache JMeter: The gold standard for open-source performance and reliability testing.
- Chaos Monkey (Netflix): Intentionally breaks your production environment to see if your system can "self-heal."
- Keploy: An AI-powered tool that captures real API traffic and turns it into test cases automatically. This is a game-changer for teams who want to eliminate "flaky tests."
Final Thoughts
A reliability test system is no longer a "nice-to-have"—it is a competitive necessity. By moving from a reactive "fix it when it breaks" mindset to a proactive reliability strategy, you protect your revenue, your reputation, and your sanity.

















Sign in to leave a comment.