
It's the industry's most common question: what's the difference between a Data Scientist and a Data Engineer?
The confusion is understandable. Both roles deal with massive datasets, require coding chops, and are absolutely critical to any modern, data-driven company. They sound similar, but in practice, they are as distinct as an architect and a construction foreman. One designs the blueprint and the other builds the foundation, but both are essential for the final structure.
In this guide, we'll strip away the buzzwords to define the core responsibilities, essential skills, typical day-to-day work, and potential career paths for each. By the end, you'll know precisely which path aligns with your strengths—and why both are necessary to turn raw data into a competitive advantage.
Quick Comparison: Data Scientist vs Data Engineer
To cut through the noise, here is the essential difference between the two roles.
Primary Goal
- A Data Scientist focuses on answering business questions, building predictive models, and generating insights.
- A Data Engineer designs and maintains the data infrastructure that makes those insights possible.
Tool Focus
- Data Scientists use modeling, statistics, and visualization tools—typically in Python or R.
- Data Engineers work with databases, ETL/ELT pipelines, and cloud platforms such as AWS, Azure, or GCP.
Output
- Data Scientists deliver machine learning models, reports, and actionable insights.
- Data Engineers produce clean datasets, reliable pipelines, and scalable data warehouses.
Key Skill
- Data Scientists specialize in statistical modeling and experimentation.
- Data Engineers master SQL, distributed systems like Spark, and data warehousing.
Where They Sit
- Data Scientists typically sit within research or analytics teams.
- Data Engineers usually belong to engineering or IT departments.
The Data Scientist is essentially the research and development engine for a company's data. They are a blend of mathematician, programmer, and storyteller.
A Data Scientist spends their day defining problems, cleaning raw data until it’s usable, exploring datasets to find hidden patterns, and building predictive models. The goal isn't just to explain what happened (analytics), but to predict what will happen (science) and recommend the best action.
Their work is cyclical and highly experimental:
- Formulate Hypotheses: "If we change X, will Y increase?"
- Model Building: Select the right algorithm (regression, neural network, etc.) and train it.
- Validation & Testing: Check the model's performance and accuracy.
- Communicating Insights: Translate complex results into business language for leadership.
The Tools of the Trade
They heavily rely on Python (for libraries like Pandas, Scikit-learn, and TensorFlow) and sometimes R. Their focus is less on engineering production-ready code and more on statistical rigor and the optimal performance of the model itself.
Specific Example with Numbers: A Data Scientist might develop a churn prediction model that identifies customers at a high risk of leaving. If this model flags 1,200 high-risk customers each month, and an outreach campaign based on that flag reduces churn by 35%, that's a direct, measurable business impact driven by the scientist's work.
🛠️ Role Deep Dive: Data Engineer
The Data Engineer is the architect and plumber of the data ecosystem. If the Data Scientist is the chef, the Data Engineer is the one who designs and maintains the kitchen, ensuring a constant, clean supply of running water, gas, and electricity.
Their primary focus is on ELT/ETL (Extract, Load, Transform) processes. They create the pipelines that efficiently move data from its various sources (website logs, third-party APIs, internal databases) into a centralized, reliable location—a data warehouse or data lake—where it can be queried by everyone, including Data Scientists and analysts.
Building the Data Highway
A Data Engineer's main concerns are:
- Scalability: Can the pipeline handle ten times the current data volume?
- Reliability: Does the pipeline run on time, every time, without breaking?
- Performance: Can a query return results in seconds, not hours?
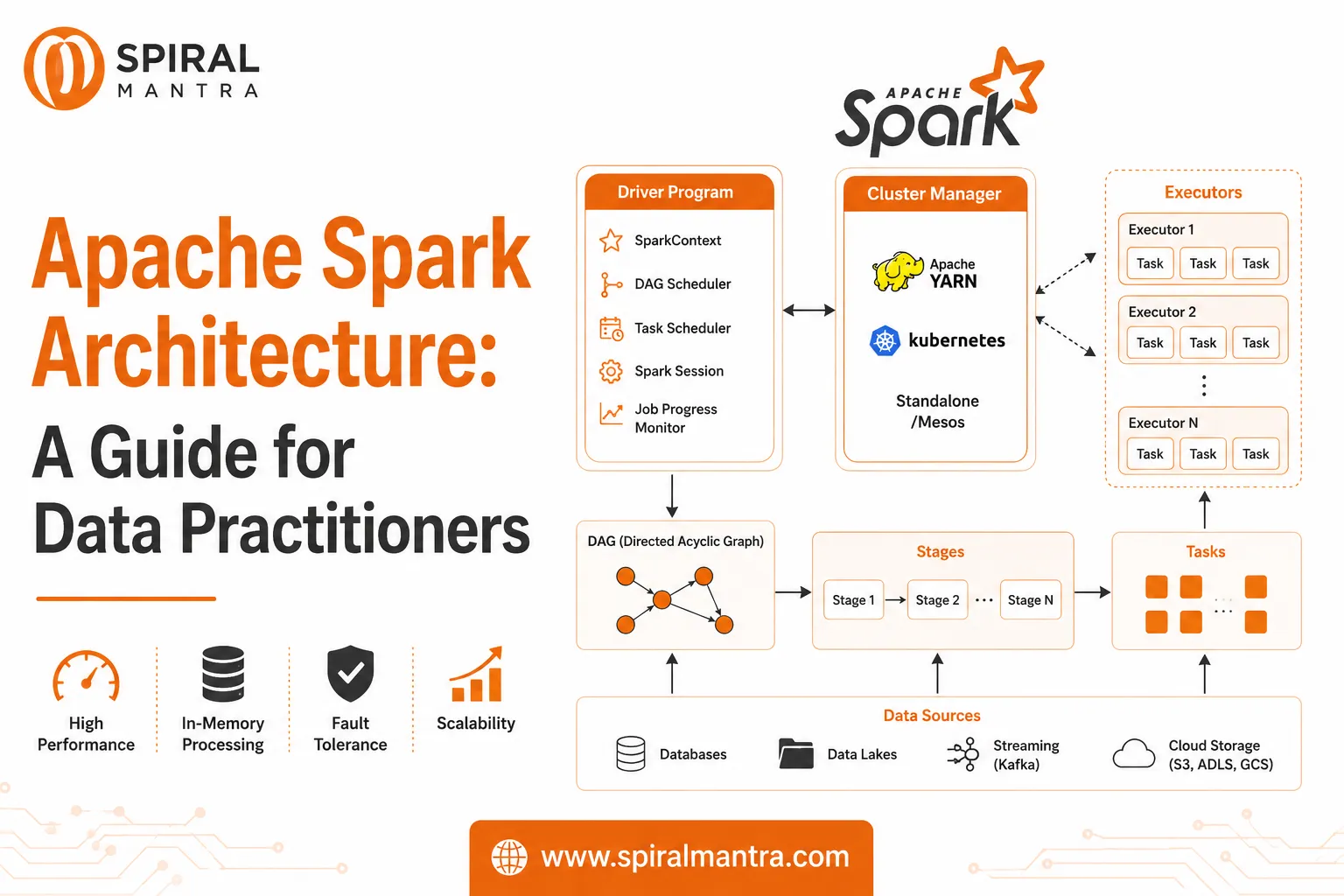
They are expert programmers (often in Python, Java, or Scala) who specialize in distributed systems like Apache Spark or Hadoop, and cloud services (AWS S3/Redshift, Google BigQuery, Azure Synapse). Their code needs to be production-quality, fault-tolerant, and designed for heavy workloads.
🌐 The Workflow: Where They Overlap and Diverge
The relationship is symbiotic. You can't have great data science without robust data engineering, and data engineering without a science application is just costly infrastructure.
Here’s a simplified view of the collaboration:
DATA GENERATION
(Web Logs, Apps, Databases, etc.)
│
▼
┌──────────────────┐
│ **DATA ENGINEER**│
│ - Build ETL/ELT │
│ - Data Cleaning │
│ - Create Warehouse│
└──────┬───────────┘
│
▼
┌──────────────────┐
│ **DATA SCIENTIST**│
│ - Feature Eng. │
│ - Model Building│
│ - Hypothesis Test.│
└──────┬───────────┘
│
▼
┌──────────────────┐
│ **DATA ENGINEER**│
│ - Deploy Model │
│ - MLOps/Monitor │
│ - Build Data APIs│
└──────┬───────────┘
│
▼
PRODUCTION/APPLICATION
The Data Engineer prepares the ground and then takes the scientist's final model to push it into a live, production environment. This final step—Model Deployment and MLOps—is increasingly a key responsibility for the Data Engineer, requiring them to deploy the model into platforms like an internal dashboard, an e-commerce backend, or even a customer-facing service like a mobile app development project. This is a crucial link, as the insights the data provides must be delivered to the end-user, often through digital products like those developed by firms specializing in mobile app development in Georgia.
🔑 Key Skill Comparison
While both Data Scientists and Data Engineers need strong problem-solving and coding abilities, their core skill emphasis differs dramatically.
Programming:
- Data Scientists typically code in Python, using libraries like Pandas, NumPy, SciPy, and scikit-learn for data manipulation and machine learning.
- Data Engineers focus on Python, Scala, or Java, emphasizing system-level and functional programming for building large-scale data systems.
Databases:
- Data Scientists use SQL mainly for querying and basic data exploration, occasionally working with NoSQL stores.
- Data Engineers dive deeper into advanced SQL, database design, and performance optimization to ensure efficient, scalable data storage.
Data Tools & Infrastructure:
- Data Scientists rely on Jupyter Notebooks, RStudio, and visualization tools for analytics and presentation.
- Data Engineers work with Apache Spark, Kafka, Airflow, and cloud platforms like AWS, Azure, or Databricks to manage and automate data flows.
Math & Statistics:
- Data Scientists require a strong foundation in linear algebra, calculus, and probability—essential for building and validating models.
- Data Engineers only need a working understanding of these concepts; their focus lies more in data systems and reliability.
System Design:
- Data Scientists think about modeling architecture—choosing the right algorithms, training setups, and validation strategies.
- Data Engineers design distributed systems, data pipelines, and warehouse architectures, ensuring data is reliable and accessible for analysis.
The Reality Check
Unpopular opinion: You won't start as a "Full Stack Data Scientist." The best way to start your career is to pick one lane and master it. Data science bootcamps often promise both, but the reality is that companies hire specialists. A Data Engineer who truly understands how to manage petabytes of data is more valuable than a Data Scientist who can build a model but can't deploy it reliably.
When To Choose What
This approach works brilliantly for B2B SaaS companies with long-term, strategic goals.
However, it fails miserably for teams that only need basic dashboarding or reports—in that case, hiring a Data Analyst makes far more sense than bringing on a full-fledged Data Scientist or Engineer.
So, how do you decide between the two?
Go for a Data Scientist if:
- You thrive in ambiguity and experimentation.
- You’re fascinated by statistics, models, and data-driven storytelling.
- You want to influence high-level business strategy with predictive insights.
Go for a Data Engineer if:
- You love structure, reliability, and building scalable systems.
- You’re obsessed with clean, optimized, and maintainable code.
- You want to own the data infrastructure that powers analytics and AI across the organization.
I spent years on the client side learning this lesson the hard way: Three data science projects failed before I figured out that the problem wasn't the model—it was the non-existent data pipeline. The data was too dirty, too slow, and too inaccessible. That's a Data Engineering problem every time.
Key Takeaways
• Data Scientists are primarily focused on discovery and prediction using statistical modeling.
• Data Engineers are primarily focused on production and delivery, building the robust pipelines that feed the models.
• The workflow is linear: the Engineer provides the clean data, the Scientist builds the model, and the Engineer deploys and maintains the model in the production environment.
• Early in your career, specialize in one role. The "data generalist" comes later with experience.
Next Steps
- If leaning Data Scientist: Start a personal project focused on a Kaggle dataset. Focus on the feature engineering and model performance, not the data cleanup.
- If leaning Data Engineer: Learn Apache Spark and Airflow (or a similar orchestration tool). Build an end-to-end ELT pipeline from a public API into a cloud database like Snowflake or BigQuery.
- Refine Your SQL: Regardless of your choice, a deep understanding of SQL is non-negotiable for success in either field.
Frequently Asked Questions
What is the typical career progression for a Data Engineer?
A Data Engineer typically moves from Junior to Mid-level, then to Senior Data Engineer, followed by Principal Engineer or an Engineering Manager role, overseeing the data platform team.
Can a Data Scientist become a Data Engineer, and vice versa?
Yes, the transition is common, particularly from Data Scientist to Data Engineer (and often to Machine Learning Engineer). The key is acquiring strong software engineering skills, as Data Engineering is fundamentally a specialized form of software engineering.
Which role has a higher earning potential?
Both roles offer excellent salaries, often topping six figures. Generally, Senior Data Engineers who specialize in distributed systems and cloud architecture often command slightly higher salaries than Senior Data Scientists, due to the high demand for reliable, scalable infrastructure.


















Sign in to leave a comment.