In today’s data-driven world, organizations rely on scalable, high-performance processing frameworks to manage massive volumes of structured and unstructured data. Apache Spark has emerged as a leading open-source engine that powers modern analytics, machine learning, and real-time data pipelines. For teams offering data engineering services, understanding Spark’s architecture is essential to designing efficient and scalable data solutions.
This guide breaks down Apache Spark architecture in a practical, easy-to-understand way for data practitioners.
What is Apache Spark?
Apache Spark is a distributed data processing framework designed for speed, scalability, and ease of use. Unlike traditional batch systems, Spark supports:
- Batch processing
- Real-time stream processing
- Machine learning
- Graph processing
Its in-memory computation model makes it significantly faster than older frameworks like Hadoop MapReduce.
Why Apache Spark Matters in Data Engineering Services
Modern data engineering services depend on tools that can:
- Process large-scale data efficiently
- Integrate with multiple data sources
- Support real-time analytics
- Scale horizontally
Apache Spark fits perfectly into this ecosystem, making it a core component of modern data platforms built on cloud technologies like AWS, Azure, and Google Cloud.
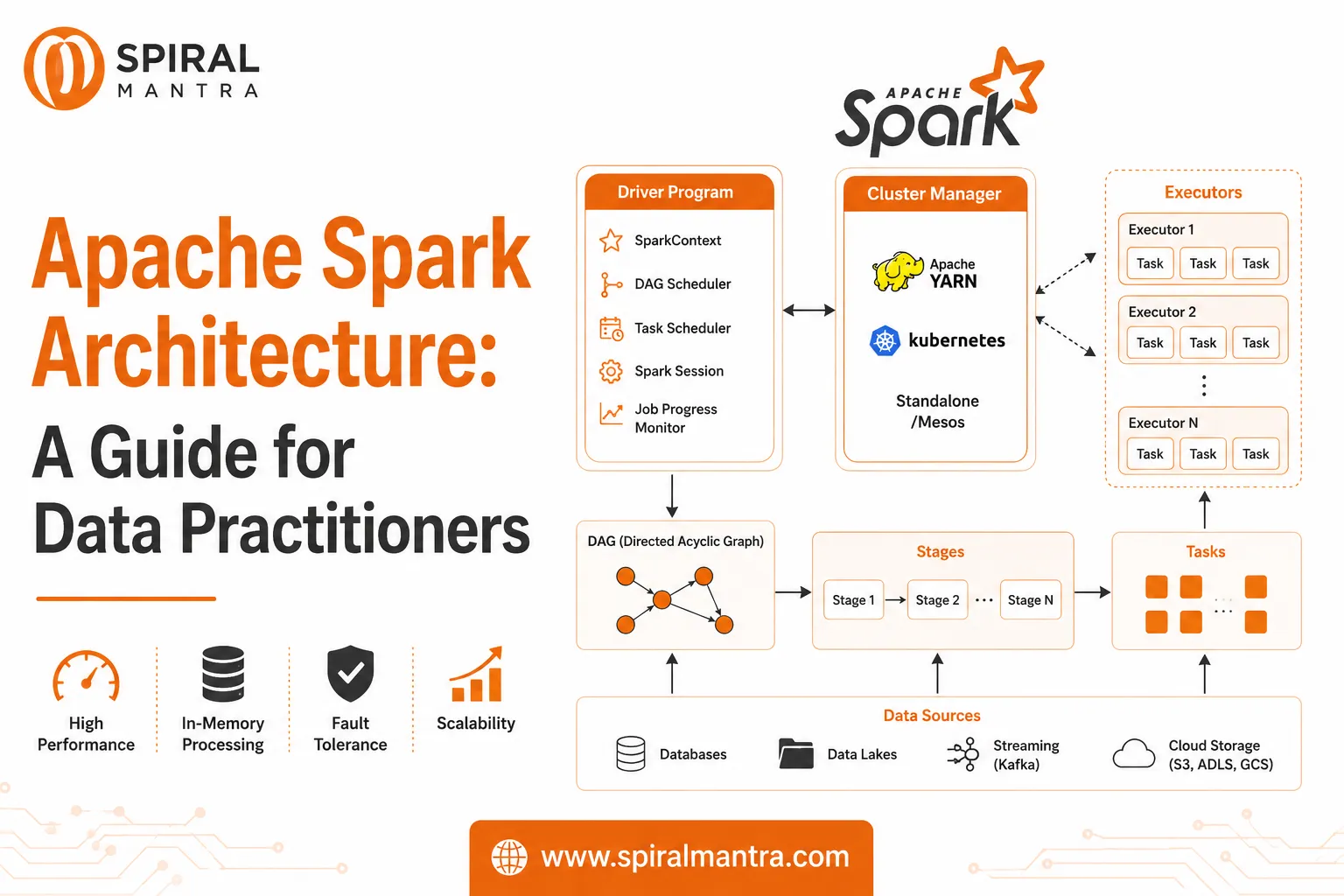
Core Components of Apache Spark Architecture
Apache Spark follows a master-slave architecture, consisting of several key components:
1. Driver Program
The Driver is the central coordinator of a Spark application.
Key responsibilities:
- Maintains the Spark session
- Converts user code into execution plans
- Schedules tasks across the cluster
- Tracks job progress
The driver runs the main function of your application and communicates with cluster managers.
2. Cluster Manager
The Cluster Manager is responsible for managing resources across the cluster.
Common cluster managers include:
- Standalone (Spark’s built-in manager)
- YARN
- Kubernetes
- Mesos
It allocates resources (CPU, memory) to Spark applications.
3. Executors
Executors are worker nodes that perform the actual data processing.
Functions:
- Execute tasks assigned by the driver
- Store data in memory or disk
- Return results to the driver
Each application gets its own set of executors, ensuring isolation and efficiency.
4. Tasks
A task is the smallest unit of work in Spark.
- Tasks operate on partitions of data
- Multiple tasks run in parallel across executors
- Task parallelism drives Spark’s performance
5. Jobs, Stages, and DAG
Spark execution is structured into:
- Job → Triggered by an action (e.g., count(), collect())
- Stage → Group of tasks without shuffling
- Task → Individual execution unit
Spark uses a Directed Acyclic Graph (DAG) to optimize execution plans.
Why DAG matters:
- Optimizes query execution
- Minimizes data shuffling
- Improves performance
Spark Execution Flow (Step-by-Step)
Here’s how Apache Spark processes data:
- User submits a Spark application
- Driver program creates a DAG
- DAG is divided into stages
- Cluster manager allocates resources
- Executors receive tasks
- Tasks process data in parallel
- Results are returned to the driver
This flow enables high-speed, distributed computation.
Key Features of Apache Spark Architecture
1. In-Memory Processing
Spark stores intermediate data in memory, reducing disk I/O and improving speed.
2. Lazy Evaluation
Transformations are not executed immediately. Spark builds a DAG and executes only when an action is triggered.
3. Fault Tolerance
Spark uses Resilient Distributed Datasets (RDDs):
- Tracks lineage
- Recomputes lost data automatically
4. Scalability
Spark can scale from a single machine to thousands of nodes.
5. Unified Engine
Supports multiple workloads:
- Spark SQL
- Spark Streaming
- MLlib (Machine Learning)
- GraphX
RDDs vs DataFrames vs Datasets
Understanding Spark abstractions is crucial for data practitioners:
| Feature | RDD | DataFrame | Dataset |
|---|---|---|---|
| Level | Low-level | High-level | High-level |
| Performance | Moderate | High | High |
| Type Safety | Yes | No | Yes |
| Optimization | Manual | Catalyst Optimizer | Catalyst Optimizer |
Best Practice:
Modern data engineering services prefer DataFrames and Datasets due to better performance and optimization.
Apache Spark in Modern Data Engineering Use Cases
Spark is widely used across industries for:
1. ETL Pipelines
- Data ingestion
- Data transformation
- Data loading into warehouses
2. Real-Time Analytics
- Processing streaming data from Kafka
- Fraud detection systems
3. Machine Learning Pipelines
- Feature engineering
- Model training using MLlib
4. Data Lake Processing
- Handling large-scale data in data lakes
- Integration with Delta Lake and Iceberg
Integration with Cloud Ecosystems
Apache Spark integrates seamlessly with modern cloud platforms:
- AWS (EMR, S3)
- Azure (Synapse, Data Lake)
- Google Cloud (Dataproc, BigQuery)
This makes it a backbone for cloud-native data engineering services.
Performance Optimization Tips
To get the best out of Apache Spark:
- Use DataFrames instead of RDDs
- Cache frequently used data
- Optimize partitioning
- Avoid unnecessary shuffles
- Use broadcast joins for small datasets
Challenges in Apache Spark Architecture
While powerful, Spark comes with challenges:
- Memory management complexity
- Debugging distributed jobs
- Performance tuning requires expertise
- Resource allocation issues
This is where experienced data engineering services providers add significant value.
Conclusion
Apache Spark architecture is designed for speed, scalability, and flexibility—making it a cornerstone of modern data platforms. From batch processing to real-time analytics, its distributed computing model enables organizations to unlock insights from massive datasets efficiently.
For data practitioners, mastering Apache Spark is not just about understanding its components, but also knowing how to optimize and integrate it within broader data ecosystems.
As businesses continue to invest in AI and analytics, leveraging Apache Spark within robust data engineering services will remain critical to building high-performance, future-ready data solutions.

















Sign in to leave a comment.