


A reliable data engineering company in USA should not only build pipelines but also ensure data accuracy, scalability, and business alignment. The blog highlights why choosing the right data engineering services partner is essential for building trustworthy data systems, avoiding expensive mistakes, and supporting long-term business growth in 2026 and beyond.
Learn Apache Spark architecture with this comprehensive guide covering DAG, Spark components, and execution flow. Ideal for data engineering services and big data professionals.
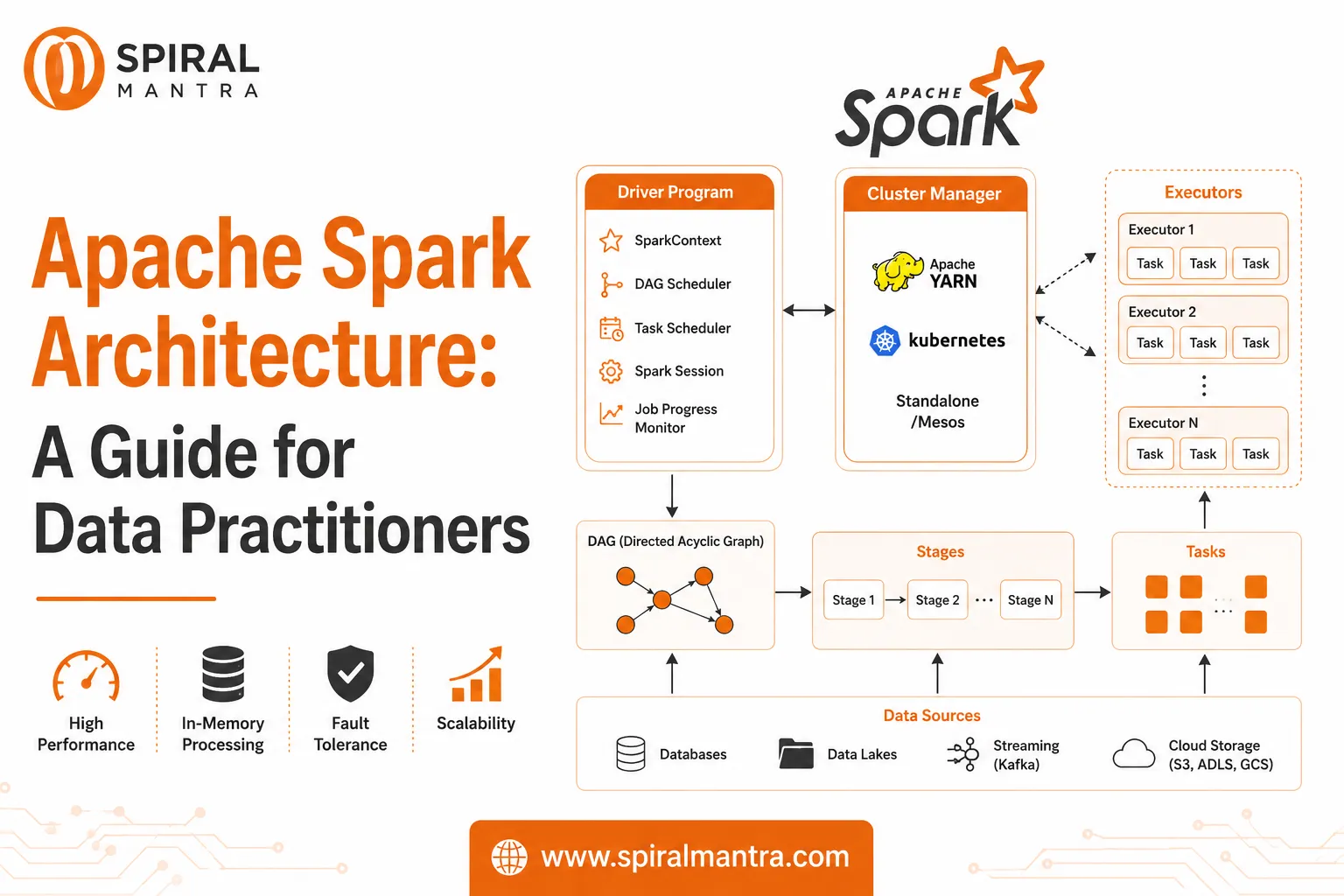
Apache Spark is a powerful, open-source framework for distributed computing, enabling fast, scalable data processing for both batch and real-time applications. It features components like Spark Core, Spark SQL, Spark Streaming, MLlib, and GraphX, which allow for efficient data transformations, real-time analytics, machine learning, and graph processing. Spark's in-memory processing, fault tolerance, and scalability make it ideal for data engineering services and data analytics services. It's widely used in industries for ETL, machine learning, real-time data processing, and complex graph analytics, offering a versatile solution for large-scale data challenges.
This complete guide to Apache Flink explains how real-time stream processing powers modern data engineering services. Learn why every data engineering company uses Apache Flink to build scalable, fault-tolerant, and AI-ready data pipelines.

In today’s digital-first world, organizations generate massive volumes of data every second—customer interactions, transactions, sensors, social m

Salesforce consulting services offer strategic guidance, implementation support, and system optimization to help businesses make the most of their Salesforce CRM platform. From streamlining operations to enhancing customer experiences, these services are essential for companies aiming to leverage Salesforce for scalable growth.