
Apache Spark has become one of the most popular open-source frameworks for distributed computing, enabling data engineering companies and data analytics services to process vast amounts of data quickly and efficiently. It is designed for both batch processing and stream processing, making it a versatile tool for modern data engineering services. In this article, we will explore Apache Spark’s architecture, core components, key features, and use cases, focusing on its role in powering scalable data engineering and analytics workflows.
Overview of Apache Spark
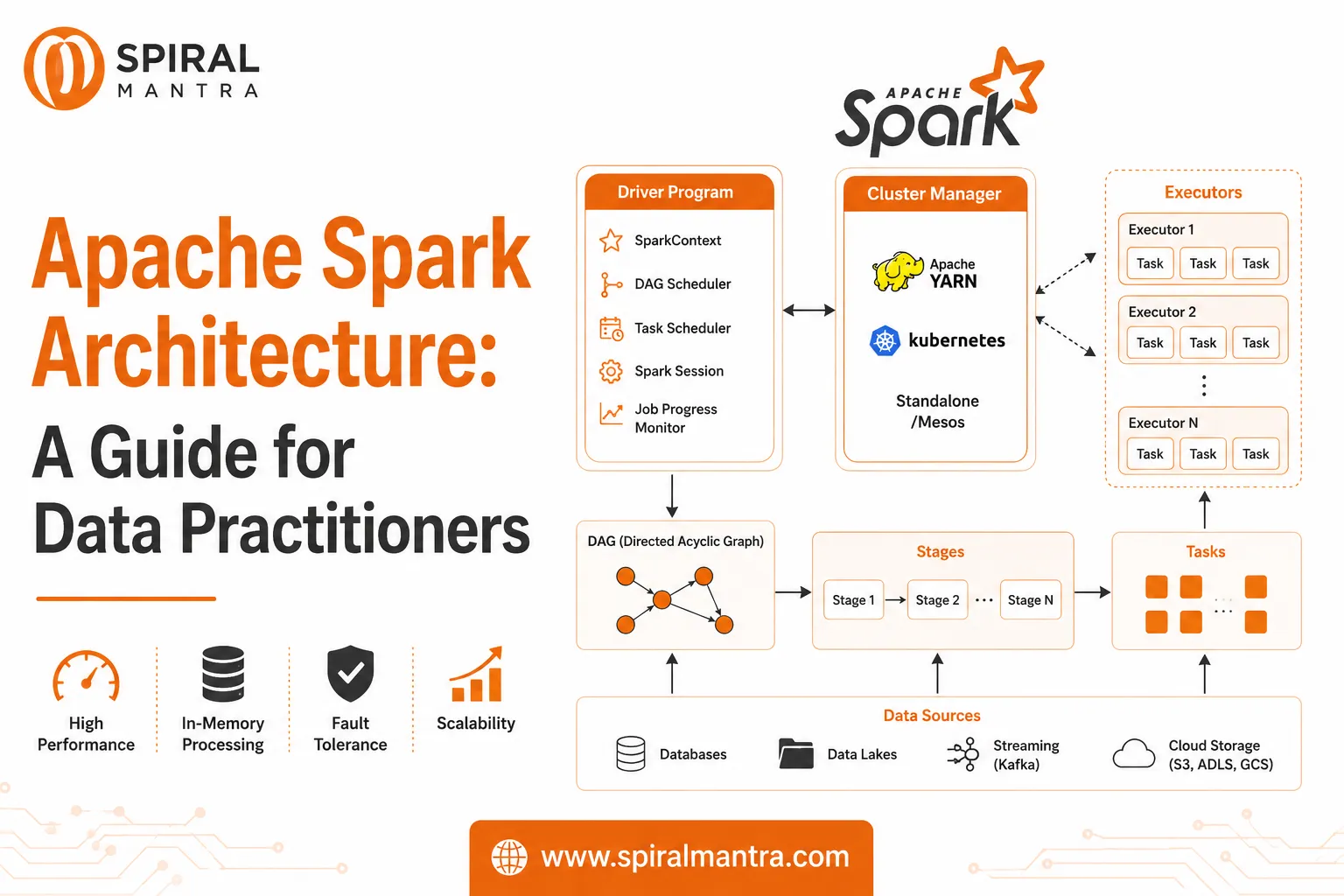
Apache Spark is an open-source, distributed computing system designed for high-performance data processing at scale. It provides in-memory processing, which makes it faster than traditional disk-based frameworks like Hadoop MapReduce. Spark can handle both structured and unstructured data, and it can be used for a wide range of tasks, from data transformation and ETL processes to real-time streaming analytics and machine learning.
For data engineering companies, Apache Spark simplifies the development of complex data pipelines, ensuring high performance, fault tolerance, and scalability. It supports both batch and real-time processing, making it suitable for a variety of data engineering and data analytics services.
Core Components of Apache Spark
- Spark Core:
- The Spark Core is the foundation of Apache Spark, providing essential functionality for task scheduling, fault tolerance, and memory management. It allows for distributed data processing using the RDD (Resilient Distributed Dataset) abstraction, which distributes data across a cluster and enables fault-tolerant, parallel processing.
- Spark SQL:
- Spark SQL enables users to interact with structured data using SQL queries. It provides both the DataFrame API and Dataset API for handling data in a structured format. By leveraging Catalyst Optimizer for query optimization, Spark SQL improves the performance of data retrieval tasks. It integrates with various data sources such as HDFS, JDBC, Hive, and Cassandra.
- For data engineering services, Spark SQL simplifies the management and transformation of structured data, while its optimization engine ensures fast query execution, making it ideal for large-scale data analytics.
- Spark Streaming:
- Spark Streaming extends Spark to handle real-time stream processing. It processes data in micro-batches and enables real-time analytics by processing data as it arrives, typically with latencies of milliseconds to seconds.
- For data analytics services, Spark Streaming is widely used for applications like fraud detection, real-time monitoring, and dynamic pricing, where timely decision-making is critical.
- MLlib (Machine Learning Library):
- MLlib is Spark’s library for scalable machine learning. It provides a suite of machine learning algorithms for tasks like classification, regression, clustering, and recommendation systems.
- Data engineering companies use MLlib to build scalable machine learning models on large datasets, enabling businesses to generate insights and predictions based on historical and real-time data.
- GraphX:
- GraphX is Spark’s API for graph processing. It allows for the efficient analysis of graph data, such as social networks, dependencies, and recommendations. With built-in graph algorithms like PageRank, connected components, and triangle counting, GraphX makes it easy for data engineering companies to perform distributed graph analytics at scale.
- SparkR and PySpark:
- SparkR and PySpark provide APIs for the R and Python programming languages, respectively. These allow data scientists and data engineers to leverage Spark's distributed computing power using familiar languages. PySpark, in particular, is popular among data analytics services for its ease of use and integration with Python-based machine learning libraries.
Key Features of Apache Spark
- In-Memory Processing:
- One of Spark’s most significant advantages is in-memory processing, where intermediate data is stored in RAM rather than being written to disk. This approach drastically reduces latency and improves the performance of iterative algorithms commonly used in machine learning and data transformation.
- Data engineering services benefit from this feature, as it allows Spark to process data much faster compared to traditional disk-based processing frameworks.
- Fault Tolerance:
- Spark ensures fault tolerance through RDD lineage. If a node fails, the lost data can be recomputed from the RDD lineage without data loss. Additionally, Spark’s checkpointing mechanism ensures that long-running jobs can recover from failures and continue processing without interruptions.
- Scalability:
- Apache Spark is designed to scale from a single machine to thousands of nodes in a cluster. Its ability to distribute data and processing across multiple nodes makes it suitable for big data applications, where large datasets need to be processed quickly and efficiently.
- This scalability is crucial for data engineering companies working with massive datasets in environments like cloud computing or on-premise clusters.
- Multi-language Support:
- Spark supports multiple programming languages, including Java, Scala, Python, and R, enabling a wide range of developers and data scientists to work with it. Its unified APIs allow developers to write Spark jobs in their preferred language while maintaining compatibility across the system.
- Rich Ecosystem:
- Apache Spark integrates with a broad range of tools in the big data ecosystem, such as Apache Kafka for real-time data ingestion, Apache HBase and Cassandra for NoSQL storage, and Hadoop for distributed storage and batch processing. This makes it an ideal choice for data engineering services that need to handle end-to-end data pipelines.
Apache Spark Use Cases in Data Engineering and Data Analytics Services
- Real-Time Data Processing:
- With Spark Streaming, organizations can process data in real-time, which is essential for applications like fraud detection and predictive analytics. This capability enables data analytics services to provide timely insights from streaming data sources like social media feeds, sensor data, and financial transactions.
- Example: A data analytics service might use Spark Streaming to monitor financial transactions in real-time, identifying fraudulent activities based on predefined patterns or anomalies.
- Machine Learning:
- MLlib provides a set of machine learning algorithms that can be run on large-scale datasets, making it ideal for applications like recommendation systems, customer segmentation, and predictive modeling. Data engineering companies use Spark to build machine learning models on data stored in data lakes or data warehouses.
- Example: A data engineering company might use Spark to train a recommendation engine on a large-scale e-commerce dataset, providing personalized product suggestions for users in real-time.
- ETL and Data Transformation:
- Apache Spark is commonly used in ETL (Extract, Transform, Load) processes. It enables data engineering services to process and transform data at scale, helping organizations clean, aggregate, and load data into data warehouses or data lakes.
- Example: A data engineering company might use Spark SQL to transform and aggregate log data from multiple sources before loading it into a central data warehouse for reporting and analytics.
- Graph Processing:
- GraphX allows organizations to perform distributed graph analytics on large-scale datasets. It’s ideal for applications such as social network analysis, fraud detection in networks, and recommendation systems.
- Example: A data analytics service could use GraphX to analyze social network connections, identifying influencers or detecting suspicious behavior patterns in user interactions.
Conclusion
Apache Spark is a high-performance, distributed computing framework that powers modern data engineering services and data analytics services. With its ability to handle batch processing, real-time stream processing, and machine learning, Spark provides the scalability, fault tolerance, and speed necessary for large-scale data analytics applications.
For data engineering companies, Apache Spark enables the creation of robust, scalable data pipelines that can process vast amounts of data in real-time or batch mode. Whether it’s building machine learning models, processing real-time data streams, or transforming large datasets, Apache Spark offers a versatile solution for big data challenges. By leveraging Spark’s capabilities, organizations can unlock new insights and make data-driven decisions faster and more efficiently.

















Sign in to leave a comment.