Efficient data processing lies at the heart of every successful data-driven application. In this guide, we delve into the key strategies and technologies for streamlining data pipelines, empowering developers to build scalable and performant data infrastructures.
Data ingestion marks the beginning of the data pipeline journey. Developers must establish robust mechanisms to collect data from diverse sources such as databases, APIs, and event streams. Leveraging tools like Apache Kafka, Apache NiFi, or Amazon Kinesis facilitates real-time data ingestion, ensuring that incoming data is captured promptly and reliably.
Once data is ingested, the focus shifts to data storage. Choosing the appropriate storage solution depends on factors like data volume, velocity, and access patterns. Relational databases like PostgreSQL and MySQL excel at structured data storage, while NoSQL databases such as MongoDB and Cassandra are tailored for handling unstructured or semi-structured data. For massive scale and flexibility, cloud-based storage solutions like Amazon S3 and Google Cloud Storage offer virtually limitless storage capacity and global accessibility.
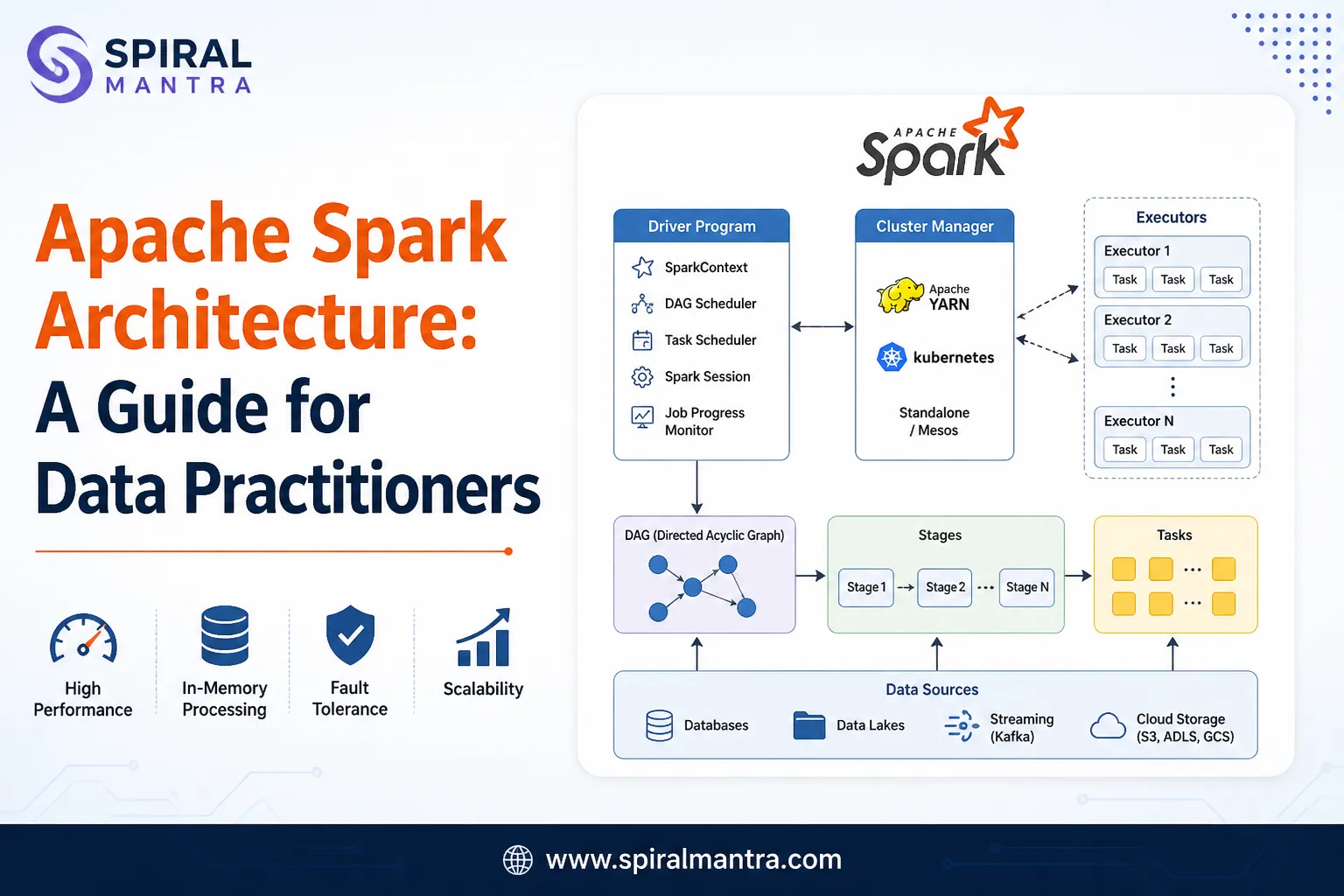
Data transformation is a critical step in the pipeline, where raw data is refined into a format suitable for analysis and consumption. Employing distributed processing frameworks like Apache Spark or Apache Flink enables developers to perform complex transformations on large datasets efficiently. These frameworks support batch and stream processing paradigms, accommodating diverse data processing requirements.
Ensuring data quality and consistency is paramount for reliable insights and decision-making. Implementing data validation and cleansing processes helps identify and rectify errors early in the pipeline. Tools like Apache NiFi, Talend, or Trifacta provide features for data profiling, cleansing, and enrichment, ensuring that only high-quality data flows through the pipeline.
Data orchestration and workflow management play a crucial role in orchestrating complex data pipelines. Platforms like Apache Airflow, Luigi, or Prefect enable developers to schedule, monitor, and manage workflows with ease. These tools offer capabilities for dependency management, parallel execution, and error handling, ensuring that data pipelines run smoothly and efficiently.
Scalability and performance optimization are essential considerations for handling growing data volumes and increasing workloads. Leveraging cloud-native technologies like Kubernetes and Docker enables developers to deploy and scale data processing workloads dynamically. Containerization and orchestration facilitate resource isolation, auto-scaling, and fault tolerance, ensuring that data pipelines can adapt to fluctuating demands seamlessly.
In conclusion, optimizing data pipelines demands meticulous attention to data ingestion, storage, transformation, and orchestration. By leveraging robust technologies and strategic planning, developers can construct scalable and resilient data infrastructures that drive actionable insights and business value. Embracing cloud-native architectures and automation enhances agility and scalability, ensuring organizations thrive in today's data-driven landscape. For further insights and resources, visit https://oak.dataforest.ai/.












Sign in to leave a comment.