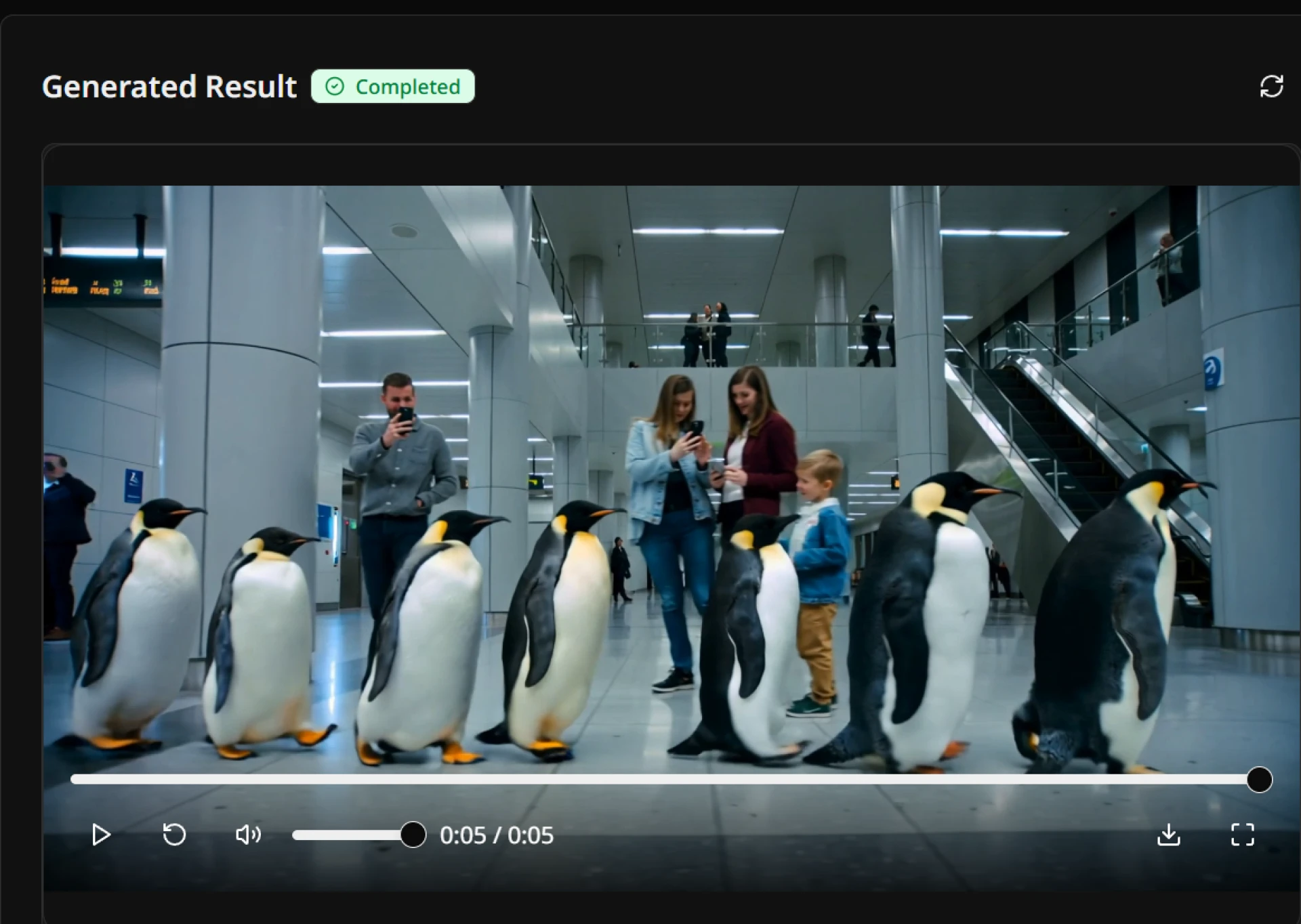
The "Text-to-Video" revolution has been moving at breakneck speed. While early models dazzled us with surreal imagery, they often suffered from a common flaw known in the industry as "temporal flickering"—where characters morph uncontrollably or backgrounds shift without logic between frames.
However, the release of the new Seedance 2.0 architecture marks a significant shift in how we approach generative video. Unlike its predecessors, which often treated video as a sequence of disjointed images, Seedance 2.0 utilizes a novel 3D-aware temporal attention mechanism.
Why Consistency Matters
For AI video to move from "toy" to "tool," it needs to understand physics. In our testing, Seedance 2.0 demonstrated a remarkable ability to maintain object permanence. If a character turns their head, their facial features remain consistent throughout the motion—a feat that has plagued many open-source models until now.
The Next Step for Creators
This leap in stability opens doors for serious narrative work. Filmmakers can now generate B-roll, storyboard animatics, or even final shots for music videos without the jarring artifacts that ruin immersion.
As the gap between generated footage and reality narrows, tools like Seedance 2.0 are becoming essential for any digital artist's toolkit. The model is currently available for public testing, allowing users to push the boundaries of what generative physics can handle.
If you are interested in testing these capabilities yourself, you can visit the official Seedance 2.0 platform to experiment with the new rendering engine.














Sign in to leave a comment.