
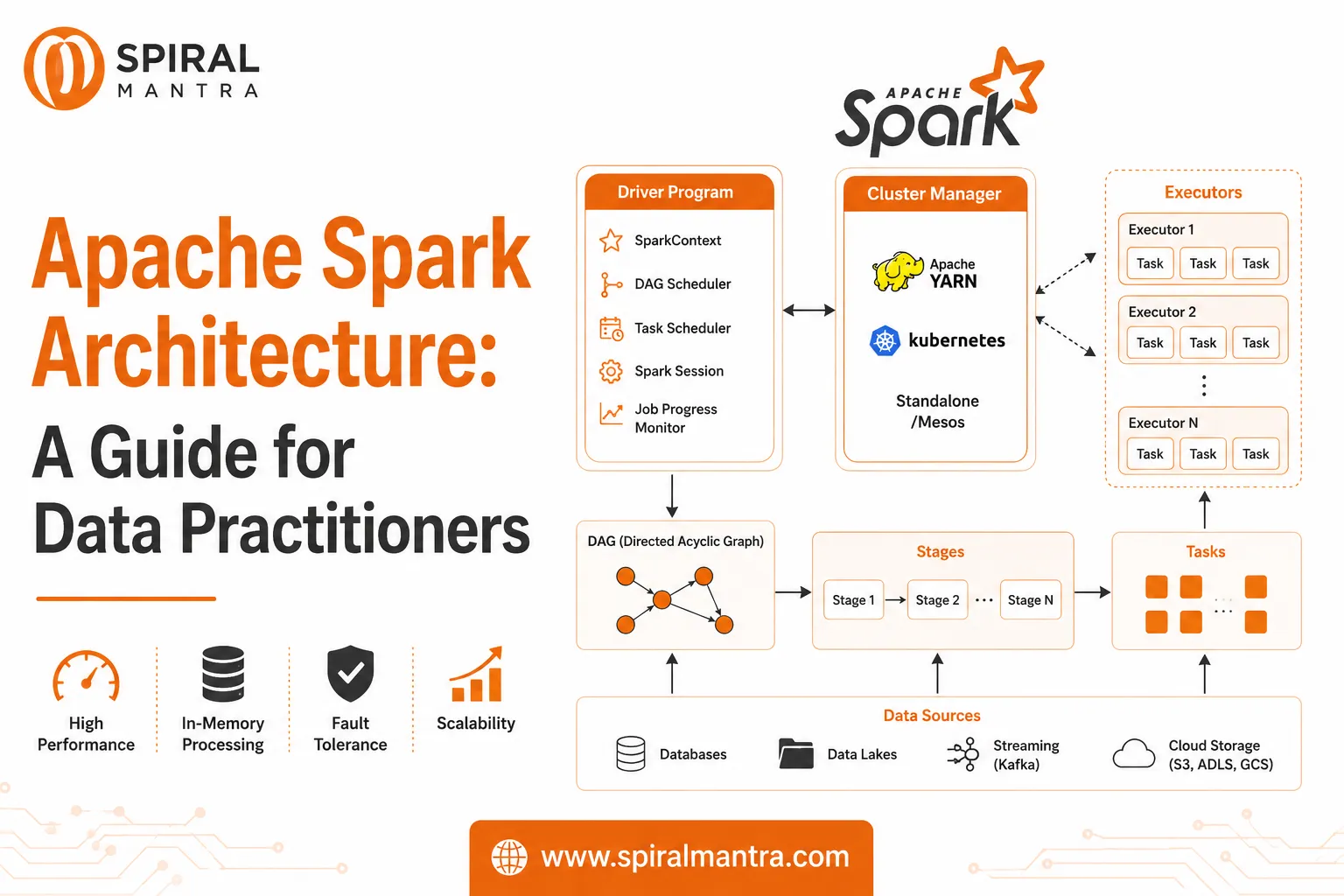
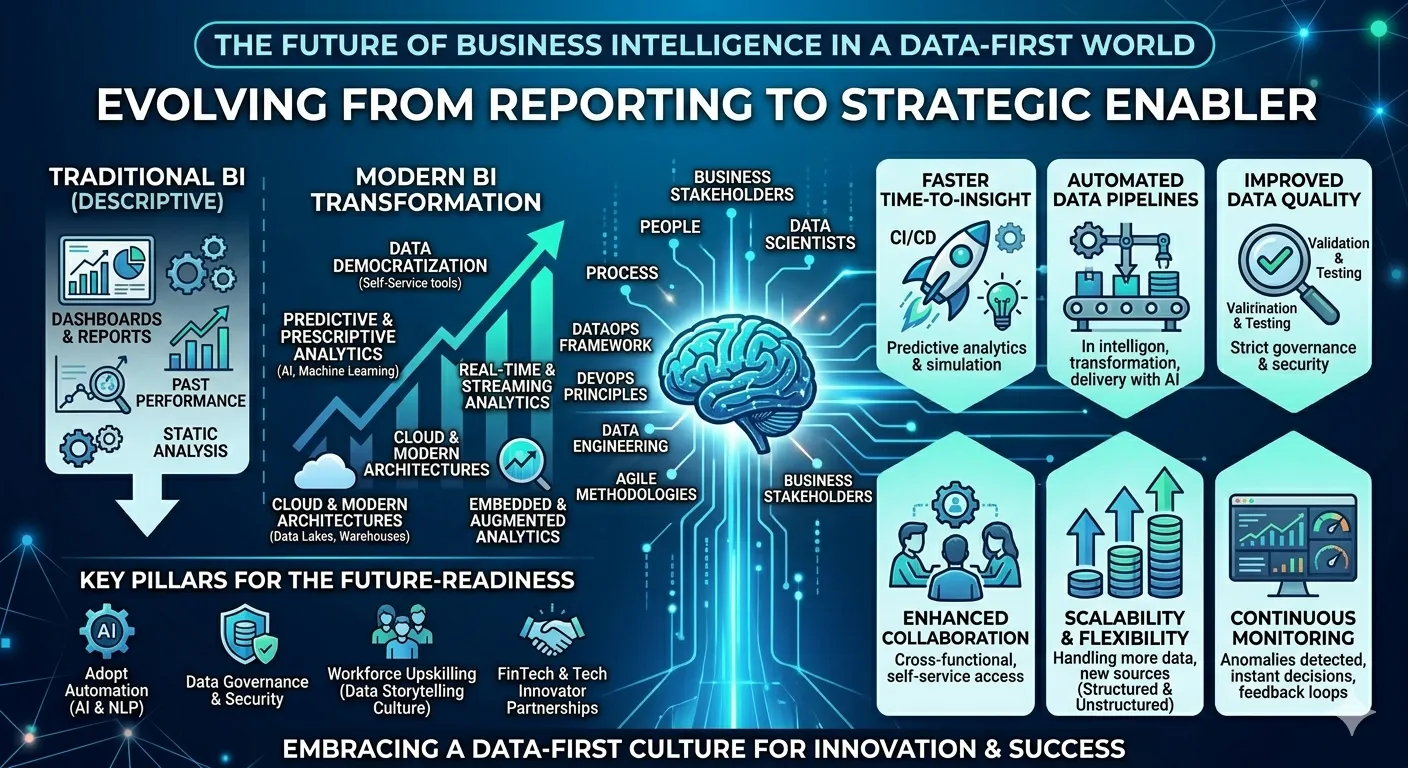
Introduction:
In today's era of artificial intelligence (AI), data annotation has become a critical aspect of developing robust and accurate machine learning models. This guide aims to provide a comprehensive understanding of data annotation, its importance in AI projects, the difference between data labeling and annotation, the process of annotating data for AI, the distinction between in-demand labeling experts and companies providing data annotation services, and an overview of data annotation types in computer vision and natural language processing (NLP).
What Data Annotation Is & Why It Matters:
Data annotation involves the process of adding meaningful labels or tags to specific data sets, enabling machines to understand and interpret the data. It plays a crucial role in training machine learning algorithms by providing the necessary information for recognizing patterns and making accurate predictions. Properly annotated data ensures that AI algorithms perform at their best and achieve desired outcomes.
How Does Data Labeling Differ From Annotation?
Data labeling and data annotation are often used interchangeably in the context of machine learning. Both terms refer to the process of adding labels to data sets. Data labeling primarily focuses on assigning descriptive labels to data, whereas data annotation encompasses a broader range of tasks, including semantic segmentation, 2D boxes, and optical character recognition (NLP). These annotations help machines understand different types of data and enable more sophisticated analysis.
Annotating Data for AI: What is the Process?
The process of annotating data for AI involves several steps that are essential for training machine learning algorithms and incorporating artificial intelligence into applications, devices, or assembly lines.
Collecting Data:
The first step in the process is collecting the data you need. The format of the data will vary depending on your specific AI task. For example, if you're building an image recognition system, you'll need to gather a substantial number of pictures of objects that the system will recognize. Similarly, if you're working with optical character recognition (OCR), you'll need a large dataset of handwritten text to automate the conversion into editable text files
Determining the Amount of Data:
The question of how much data is needed is a common one, and there is no definitive answer. Generally, more data is considered better, as a larger dataset allows for the discovery of hidden patterns through artificial intelligence techniques, often referred to as big data. For instance, an online retail store can use vast amounts of data to provide personalized recommendations to users based on their preferences and similarities with other users.
Avoiding Overfitting:
Overfitting, or overtraining, is a phenomenon where a machine learning model becomes too specialized in the training data and performs poorly on new, unseen data. While having a significant amount of data helps mitigate overfitting, it's important to strike a balance. Rather than obsessing over the quantity of data, focus on the quality and relevance of the data. Collecting the right data that represents the problem domain is crucial for training machine learning algorithms effectively.
Annotation Standards:
Instead of fixating on the quantity of data, it is vital to consider the standards for annotation. Annotating data is a time-consuming and costly process, so it's important to ensure that the data is annotated with high quality and accuracy. Well-annotated data provides the necessary information for machine learning algorithms to learn patterns and make accurate predictions. Annotation standards include factors such as consistency, precision, and relevance to the AI task at hand.
In-Demand Labeling Experts vs. Companies that Provide Data Annotation:
When embarking on an AI project, organizations face a choice between hiring in-demand labeling experts or partnering with companies specializing in data annotation services.
In-demand labeling experts are skilled professionals with expertise in data annotation. They have a deep understanding of specific annotation tasks and can provide tailored solutions to meet project requirements. Hiring in-house experts can offer more control over the annotation process, as they are directly involved in the project and can adapt to evolving needs.
On the other hand, companies that provide data annotation services offer several advantages. These companies have dedicated teams of experienced annotators who are well-versed in various annotation techniques and tools. They can handle large-scale annotation projects efficiently and provide faster turnaround times. Outsourcing data annotation to specialized companies also allows businesses to save time, reduce costs, and access a wider range of annotation expertise.
Ultimately, the decision between in-demand labeling experts and data annotation companies depends on the specific needs and resources of the organization. Both options have their merits and can contribute to the successful completion of AI projects through accurate and reliable data annotation.
Types of Data Annotation: (computer vision) CV & (natural language processing) NLP:
Data annotation tasks can be broadly categorized into computer vision (CV) and natural language processing (NLP). CV focuses on image-related data, including image categorization, semantic segmentation, 2D boxes, 3D cuboids, polygonal annotation, and keypoint annotation. NLP, on the other hand, deals with text-based data and includes tasks such as text classification, optical character recognition (OCR), named entity recognition (NER), and intent/sentiment analysis.
Types of Data Annotations in Computer Vision:
Computer vision encompasses various annotation tasks critical for training AI models:
Image Categorization: ML algorithms learn to classify images into predefined categories, enabling recognition of objects or features within the images.Semantic Segmentation: Machines are trained to associate each pixel of an image with a specific class of objects, allowing for precise object recognition and understanding.
2D Boxes: Objects in images are annotated by drawing bounding boxes around them, providing spatial information and aiding in object detection and tracking.
3D Cuboids: This annotation type involves defining 3D bounding boxes around objects in images, crucial for tasks like autonomous driving and object manipulation.
Polygonal Annotation: Objects with complex shapes are annotated using polygonal outlines, offering detailed information for object recognition.
Keypoint Annotation: Specific points of interest, such as facial landmarks or joint positions, are annotated to enable precise localization and tracking.
Data Annotation Types in NLP:
NLP relies on different annotation tasks to extract meaning from text-based data:
Text Classification: Text documents are labeled with predefined categories, allowing machines to understand and categorize text based on its content.Optical Character Recognition (OCR): Handwritten or printed text within images is transcribed into machine-readable text, enabling analysis and indexing of textual information.
Named Entity Recognition (NER): Entities such as names, locations, organizations, or dates are identified and annotated in text, aiding in information extraction and analysis.
Intent/Sentiment Analysis: Annotation of text based on the intent or sentiment expressed, enabling machines to understand the underlying purpose or emotional tone.
So what exactly does data annotation mean?
Data annotation plays a pivotal role in the development and advancement of artificial intelligence. By labeling data with relevant information, data annotation enables machines to learn, interpret, and perform complex tasks that were once exclusive to human capabilities. Annotated data provides the necessary context and structure for machine learning algorithms, allowing them to identify patterns, make accurate predictions, and generate meaningful insights. The process of data annotation not only helps machines understand the world as we do but also fuels innovations in various domains, such as computer vision, natural language processing, and speech recognition. With the availability of large and well-annotated datasets, the potential for AI applications grows exponentially, driving advancements in technology and transforming industries across the globe.
Final Thought:
Data annotation is an indispensable part of AI development, as it bridges the gap between raw data and meaningful insights. By providing labeled data, annotation empowers machine learning algorithms to think like humans, resulting in accurate predictions and better decision-making. Whether through in-house expertise or collaboration with data annotation service providers, organizations must prioritize high-quality annotation to ensure the success of their AI projects.
In conclusion, understanding data annotation, its process, and its various types in computer vision and NLP is crucial for leveraging the full potential of AI and building intelligent systems that can revolutionize various industries.













Sign in to leave a comment.