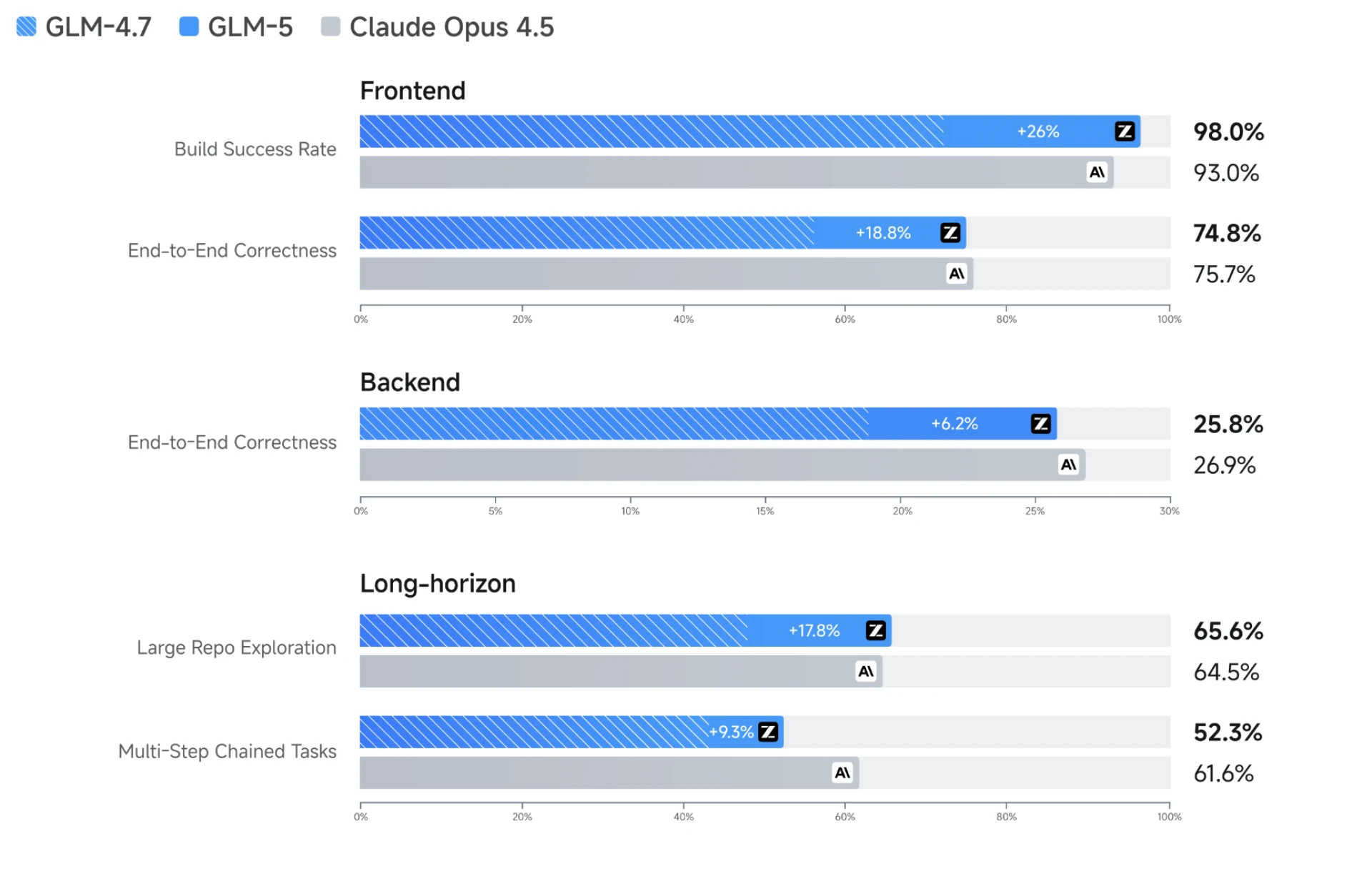
Today, I was genuinely impressed by GLM-5’s agentic coding ability.
Hi, I’m PaperAgent — despite the name, I’m not an agent.

At the end of last month, Anthropic released the *2026 Agentic Coding Trends Report*. One point in that report stuck with me more than anything else: the real shift isn’t about AI helping humans write code anymore. It’s about humans acting as system architects, coordinating agents with different roles to build entire systems.
Around the same time, Claude Opus 4.6 and GPT-5.3 Codex were released almost back-to-back. That timing wasn’t accidental. The competition has clearly moved on — not “who writes better code,” but “who can actually build systems.”
Long-horizon agents, in practice
To be honest, I didn’t expect an open-source model to catch up this quickly. The window before the end of the year was short, and most serious agentic coding demos so far have relied on expensive proprietary models.
Then I spent time testing GLM-5.
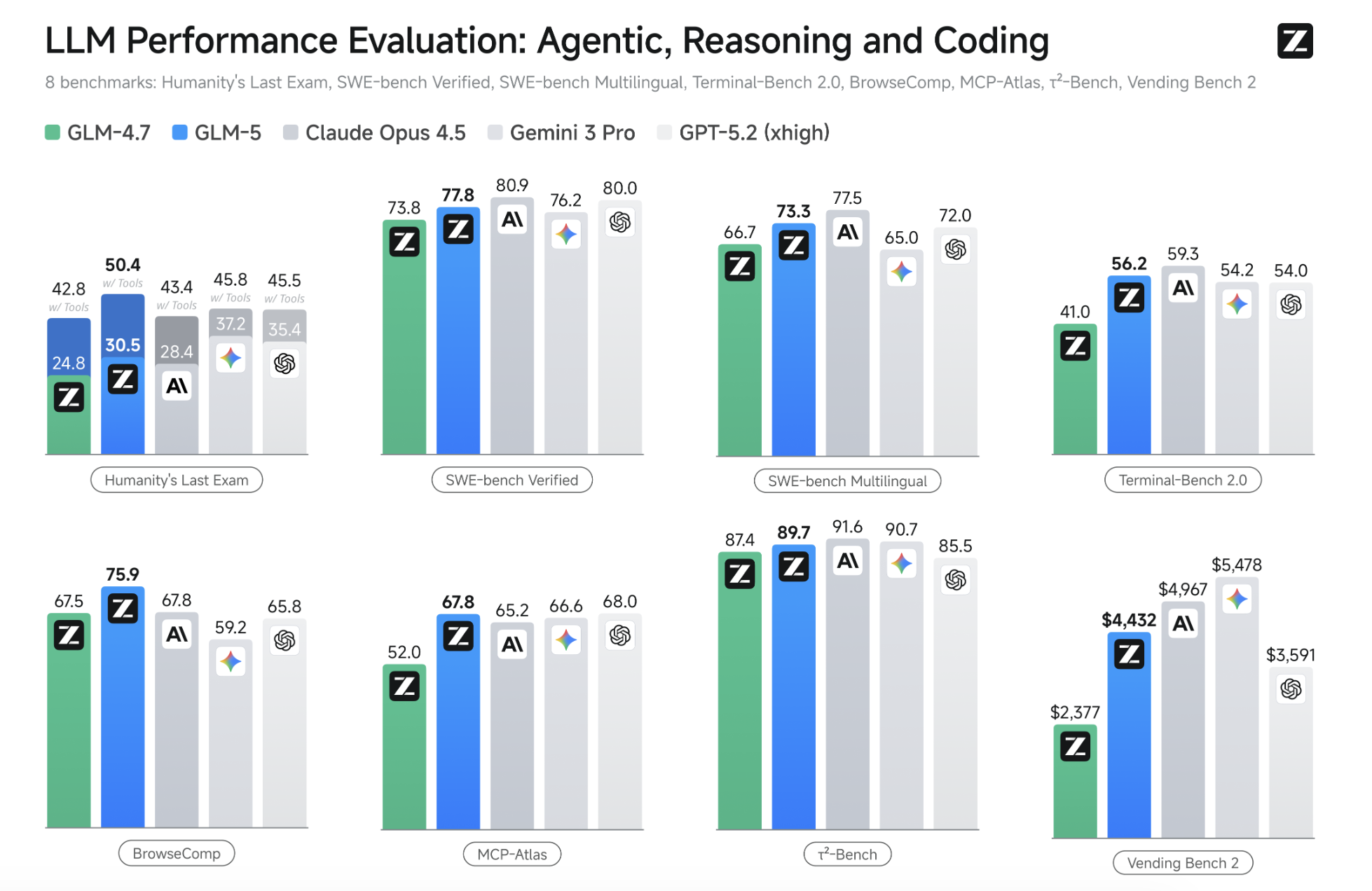
What surprised me wasn’t just raw capability, but how well it handled **multi-stage, long-running system tasks** — the kind that usually fall apart after a few iterations.
Before pushing it into anything serious, I gave it a small warm-up: build a fireworks show using a single HTML file. Even that told me something important. GLM-5 wasn’t narrowly optimized for backend logic. Visual structure, animation timing, interaction details — none of that was missing. If anything, it felt more balanced than previous versions.
That gave me enough confidence to move on.
Building a real multi-agent “town”
Recently, projects like OpenClaw (formerly Clawdbot) have become popular. One experiment I found interesting placed multiple agents into a shared “town” where they could roam and interact.
Fun idea — but limited.
Those agents share an environment, yet they don’t really have deep memory, long-term goals, or social relationships. Without those, you don’t get emergent behavior. You just get scripted interaction.
So I gave GLM-5 a harder task:
design and implement, from scratch, a **self-running multi-agent society** — agents with memory, goals, and relationships, living and interacting over time.
This wasn’t about plugging into an existing framework. GLM-5 had to reason about the architecture itself. To its credit, it immediately recognized the complexity and slowed down instead of rushing into code.
It started by proposing a full system plan: backend services, frontend visualization, LLM coordination, vector storage, real-time communication. The structure was clean and familiar to anyone who’s built distributed systems before.
The core pieces were clearly separated:
- a world simulation engine for time, rules, and global events
- independent agent services, each with private memory, goals, and relationship graphs
- a persistence layer capable of serializing long-running agent state
This wasn’t experimental spaghetti code. It followed classic microservice thinking, which is exactly what you want if you care about scalability and consistency.
What really mattered, though, was whether it held up over time.
I ran the simulation for hours. Agents retained individual memories — things like “the baker owes me money” or “I met the blacksmith yesterday” — and recalled them correctly during later interactions. There was no role drift, no identity confusion. In the end, the system produced coherent social narratives without manual correction.
That alone would’ve been a solid result.
Refactoring a 35,000-line legacy backend
The second test was much less playful.
TrustGraph is an open-source project aimed at improving knowledge graph extraction using ontologies. In theory, it solves real problems that systems like GraphRAG struggle with — duplicated entities, inconsistent types, messy graphs.
In practice, the core extraction pipeline is a large, fragile monolith.
The main module (`trustgraph-flow`) contains over **320 files and roughly 35,000 lines of algorithmic code**. Refactoring this into something robust and modular isn’t a demo task — it’s the kind of work that normally takes a team and a budget.
With proprietary models, cost becomes a real constraint. Deep refactoring like this means dozens of interaction rounds. Each run adds up.
So I handed the entire problem to GLM-5.
First, it did what most tools skip: it read the existing code carefully and reconstructed the actual business logic — entity extraction, relation classification, conflict resolution, graph merging. It didn’t treat the system as a black box.
Instead of designing one giant “do everything” agent, GLM-5 proposed a small team: a coordinator, an entity extractor, a relation extractor, and a validator. Each had clearly defined inputs and outputs. The resulting structure was understandable, not just functional.
During integration testing, things broke — as they always do.
What looked like a simple environment configuration issue turned out to be something deeper: inconsistent and ambiguous Python import paths across modules. GLM-5 traced the entire call chain, unified the imports, and fixed the architectural inconsistency at its root.
After that, the test suite ran cleanly. All modules passed.
Why this felt different
After finishing both projects, I just sat there for a moment.
Claude Opus 4.6 and GPT-5.3 Codex are undeniably strong models. But when I use them, there’s always a quiet tension in the background. Every extra question has a cost. Every debugging iteration feels like spending money to rent someone else’s brain.
GLM-5 didn’t feel like that.
Watching it take apart a 35,000-line legacy system — not just patching errors, but reasoning all the way from path issues to architectural consistency — felt different. Slower, calmer, more deliberate.
For the first time in the open-source space, this felt less like “an assistant that writes code” and more like **a system-level thinking partner**.
If you’re looking for an AI that understands architecture, can survive long projects, and is willing to sit with you in the terminal digging through logs — GLM-5 is worth trying something genuinely ambitious with.















Sign in to leave a comment.