
What Is a Data Pipeline?
A data pipeline is a structured process that moves data from its source to its destination in a reliable and automated way. It defines how data is collected, transformed, validated, and delivered so it can be used for analytics, reporting, and machine learning.
Data pipelines form the backbone of modern data systems. Without them, organizations would be forced to manually move and prepare data, making large-scale analytics and AI practically impossible.
How Data Pipelines Work
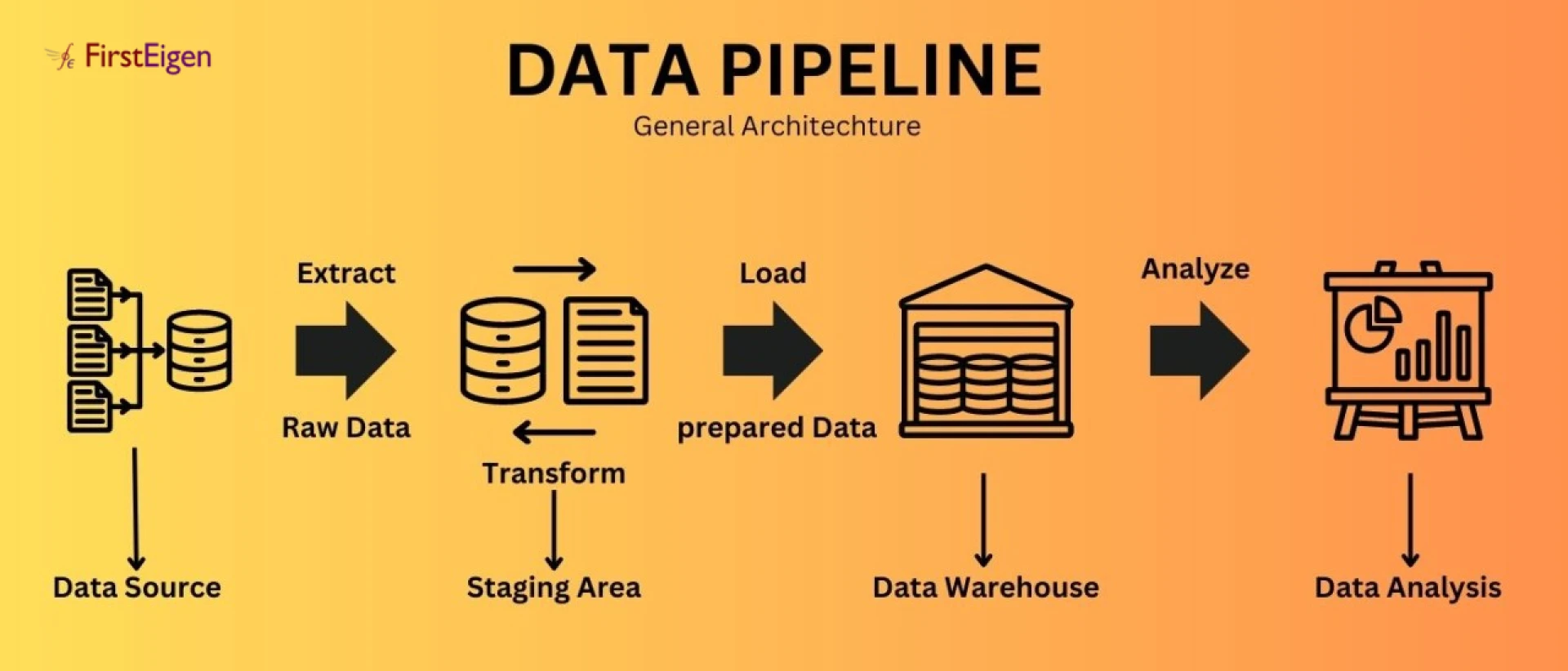
Most data pipelines follow a series of connected stages:
1. Data Ingestion : Data is collected from multiple sources such as transactional databases, SaaS applications, APIs, logs, or IoT devices.
2. Data Processing and Transformation : Raw data is cleaned, formatted, enriched, and transformed to match business and analytical requirements.
3. Data Storage : Processed data is stored in data lakes or data warehouses, often on cloud platforms.
4. Data Consumption : The final data is consumed by dashboards, reports, AI models, or downstream applications.
These steps may run in batch mode, real time, or a combination of both, depending on the use case.
Why Data Pipelines Matter
Data pipelines enable organizations to:
- Maintain consistent and repeatable data flows
- Support analytics and business intelligence
- Power machine learning and AI models
- Generate regulatory and financial reports
- Reduce manual data handling and errors
When data pipelines operate correctly, teams can rely on data for decision-making. When they fail, the impact spreads quickly across the organization.
Common Challenges with Data Pipelines
Many organizations assume their data pipelines are reliable because jobs complete successfully, and systems show no errors. However, this often hides deeper issues.
Common data pipeline problems include:
- Silent data errors that don’t trigger failures
- Schema changes that break downstream logic
- Incomplete or duplicate records
- Data drift affecting AI models
- Incorrect transformations or business rules
These issues may not stop pipelines from running, but they can severely impact data accuracy and trust.

Beyond Movement: Trust in Data Pipelines
Moving data from one system to another is only part of the equation. Modern data pipelines must also ensure that the data being delivered is accurate, consistent, and usable.
This requires:
- Continuous data validation
- Monitoring data behavior, not just job status
- Detecting anomalies and inconsistencies early
- Preventing bad data from reaching downstream systems
This is where platforms like FirstEigen play a critical role.
How FirstEigen Supports Reliable Data Pipelines
FirstEigen strengthens data pipelines by adding autonomous data validation and observability across the entire pipeline lifecycle.
Instead of relying on static rules or manual checks, FirstEigen uses AI to learn normal data patterns and identify deviations automatically. This allows teams to detect silent data issues even when pipelines appear to function normally.
Key benefits include:
- End-to-end visibility across data pipelines
- Early detection of data quality issues
- Reduced manual rule creation
- Improved confidence in analytics and AI outputs
By focusing on data trust rather than just pipeline execution, FirstEigen helps organizations prevent downstream failures.
Characteristics of Strong Data Pipelines
Reliable data pipelines typically share the following traits:
- Automation across ingestion, transformation, and delivery
- Scalability to handle growing data volumes
- Continuous validation of data quality
- Minimal manual intervention
- Clear visibility into data health
Organizations that invest in these capabilities experience fewer data issues and faster decision-making.
Why Data Pipelines Need More Than Monitoring
Traditional monitoring tools focus on whether pipelines run successfully. However, a successful run does not guarantee correct data.
Trusted data pipelines require:
- Validation of content, not just completion
- Detection of silent and logical errors
- Proactive alerts before business impact
FirstEigen addresses this gap by validating data itself, not just pipeline processes.
Conclusion
A data pipeline is the foundation that enables organizations to collect, process, and use data at a scale. While moving data efficiently is essential, ensuring that data is accurate and trustworthy is just as important.
By combining data pipelines with autonomous validation and observability, platforms like FirstEigen help organizations build reliable data systems that support analytics, AI, and business decisions with confidence.













Sign in to leave a comment.