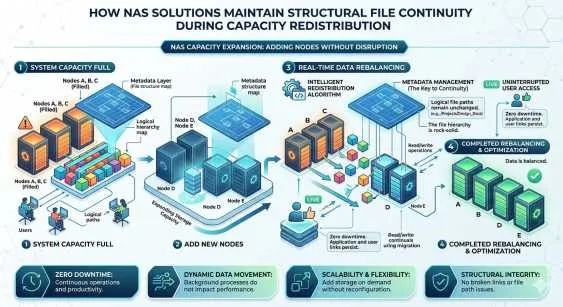
As data volumes grow at an exponential rate, enterprise IT environments require storage architectures that can expand seamlessly without disrupting ongoing operations. Adding new physical or virtual nodes to an existing storage cluster is a standard procedure. However, the background process of rebalancing that data across the newly expanded cluster presents a significant technical challenge. Ensuring that applications and users experience zero downtime or file corruption during this phase is critical for enterprise continuity.
This structural file continuity is the cornerstone of modern file systems. When an administrator adds capacity, the system must redistribute data blocks to ensure optimal utilization across all available drives and nodes. If the storage architecture mishandles this redistribution, it risks breaking file paths, corrupting metadata, or causing severe latency spikes.
Advanced NAS solutions have evolved to handle this complex data choreography automatically. By decoupling the logical file structure from the physical storage hardware, these systems allow data to migrate across disks while maintaining a consistent namespace. This abstraction ensures that client applications accessing a file have no awareness that the underlying data blocks are actively moving between servers.
Understanding the internal mechanisms that allow NAS solutions to achieve this uninterrupted data availability provides valuable insight for storage architects and system administrators. By examining the roles of metadata management, distributed hashing, and background rebalancing protocols, we can see exactly how these systems protect data integrity during capacity redistribution.
The Architecture of Scale Out Storage
Unlike traditional scale-up systems that rely on adding disk enclosures to a single, monolithic dual-controller setup, scale-out storage distributes the workload and capacity across multiple independent nodes. Each node contributes CPU, memory, and disk capacity to a unified cluster.
Node Addition and Data Balancing
When a new node joins a scale out storage cluster, the system immediately recognizes the new resources. However, leaving the new node empty while existing nodes remain near capacity defeats the purpose of the expansion. The system must redistribute existing data to the new node to equalize the storage utilization and distribute the client access load.
This capacity redistribution is governed by specialized algorithms designed to minimize the impact on foreground client operations. The cluster continuously monitors I/O loads, prioritizing read and write requests from users while allocating idle resources to the background data migration.
Mechanisms for Structural File Continuity
Maintaining structural file continuity requires the system to track exactly where every piece of data resides at any given microsecond. NAS solutions achieve this through sophisticated metadata architectures and advanced data protection schemes.
Metadata Management and Distributed Hash Tables
In advanced NAS storage environments, metadata—the data that describes the files, such as permissions, creation dates, and physical block locations—is often managed independently of the actual file data. Many systems utilize a Distributed Hash Table (DHT) to track this information.
When a file is written to the NAS storage cluster, the system assigns it a unique mathematical identifier using a hashing algorithm. The DHT maps this identifier to specific physical drives and nodes. During capacity redistribution, as blocks of data move from older nodes to the newly added node, the system simply updates the DHT in real-time. Because client applications query the DHT rather than hardcoded physical addresses, the file paths remain completely static and unbroken from the user's perspective.
Erasure Coding and Replication in NAS Storage
To protect against hardware failures, NAS solutions employ erasure coding or data replication. During a redistribution event, these protection mechanisms play a dual role. They ensure that even if a drive fails while data is moving, no information is lost.
In an erasure-coded environment, a file is broken into fragments, expanded with parity data, and spread across multiple nodes. When a cluster expands, the scale out storage system recalculates the optimal layout for these fragments. It moves pieces of the parity set or data chunks to the new node, verifying the integrity of each block via checksums before deleting the original copy from the old node. This cryptographic verification guarantees that the redistributed file is a perfect, continuous match of the original.
Managing Capacity Redistribution Seamlessly
The actual movement of data must be throttled and managed to prevent network congestion or CPU bottlenecks on the storage nodes. Enterprise-grade systems use adaptive background rebalancing processes.
Background Rebalancing Processes
Adaptive rebalancing works by constantly polling the cluster for available I/O bandwidth. If the NAS solutions detect heavy client traffic, such as a large database backup or a surge in user access, they will throttle the data redistribution speed. Conversely, during off-peak hours, the system accelerates the redistribution.
Furthermore, these systems utilize atomic operations for metadata updates. An atomic operation guarantees that a change (like updating a file's location after it moves to a new node) is completely finished before the system acknowledges it. If a power failure occurs midway through the update, the operation rolls back to its previous state. This ensures that a file is never left in a corrupted, half-moved state, thereby guaranteeing structural file continuity.
Frequently Asked Questions
What happens if a node fails during capacity redistribution?
Because modern NAS storage uses erasure coding or mirroring, the system maintains high availability even during a failure. If a node fails while data is rebalancing, the cluster uses the parity data or replica blocks on the surviving nodes to continue serving files to clients while automatically suspending the migration until the hardware is restored.
Does adding capacity to scale out storage cause downtime?
No. True scale out storage architectures are designed for non-disruptive operations. You can add nodes, upgrade firmware, and redistribute capacity while the system remains online and fully accessible to users.
How long does the rebalancing process take?
The duration depends heavily on the volume of data being moved, the network bandwidth between nodes, and the current workload on the NAS solutions. Because the system throttles background tasks to prioritize active client I/O, a large redistribution can take anywhere from a few hours to several days, all without disrupting file continuity.
Optimizing Your Enterprise Storage Infrastructure
Maintaining structural file continuity during capacity redistribution is a complex engineering feat that modern storage architectures handle with remarkable efficiency. By leveraging distributed metadata, real-time hash tables, and adaptive background processing, these systems ensure that data remains highly available and structurally sound, no matter how large the cluster grows.
If your organization is evaluating new storage architectures, prioritizing systems that offer non-disruptive capacity redistribution is essential for long-term operational stability. Review your current infrastructure limits and consider consulting with a storage architect to determine if migrating to a more advanced, clustered architecture aligns with your data growth projections.


















Sign in to leave a comment.