
In the traditional world of enterprise data storage, reliance on a single "brain" to manage everything was a necessary evil. For years, organizations depended on monolithic storage systems where one or two controllers held the keys to the kingdom—specifically, the metadata that told the system where every byte of data lived. If that controller struggled, performance tanked. If it failed, data access vanished.
This architecture, often found in legacy Network Attached Storage (NAS) systems, created a precarious single point of failure. It was a bottleneck that limited growth and threatened uptime.
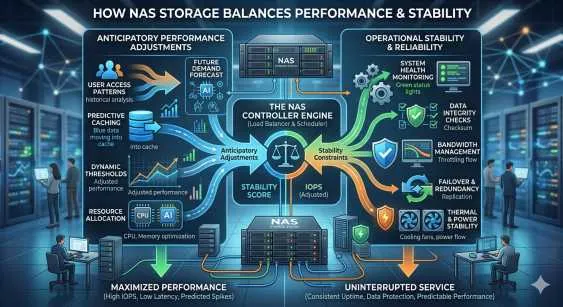
Enter scale-out NAS. By reimagining how storage is architected, particularly through the clever distribution of metadata, modern systems have effectively eliminated the single-controller failure scenarios that kept IT administrators awake at night. This shift isn't just a technical upgrade; it's a fundamental change in how we approach data reliability and performance.
The Problem with the "Master" Controller
To appreciate the solution, we must first understand the flaw in traditional scale-up architecture. In a standard dual-controller NAS system, all metadata—the critical map of the file system structure, permissions, and file locations—is typically owned by a specific controller.
Think of it like a massive library with millions of books but only one librarian who knows where everything is shelved. If that librarian goes on a lunch break or calls in sick, the library is paralyzed. You can have miles of empty shelves (storage capacity), but without the librarian (metadata controller), you can't find or retrieve a single book. Scale out NAS architectures solve this bottleneck by distributing metadata and workloads across multiple nodes, ensuring performance and access don’t depend on a single point of control.
The Bottleneck Effect
As data volumes grow, the limitations of this "master" controller become obvious.
- Performance cliffs: As you add more files, the metadata table grows. The controller has to work harder to look up file locations, eventually slowing down the entire system regardless of how many disk drives you add.
- Failover latency: If the active controller fails, the passive controller must take over. This process involves mounting file systems and replaying logs, which can take minutes. In high-transaction environments, minutes of downtime are unacceptable.
- Scalability limits: You can add more storage shelves (expansion trays) to increase capacity, but you cannot easily add more performance. You are forever limited by the CPU and RAM of the head unit controllers.
Demystifying Scale-Out NAS Architecture
Scale-out NAS takes a completely different approach. Instead of a single head unit managing shelves of dumb disks, a scale-out system is composed of nodes. Each node contains its own compute power (CPU), memory (RAM), network interface, and storage media.
When you cluster these nodes together, they act as a single, logical system. But the real magic lies in how they handle the "librarian" work—the metadata.
True Metadata Distribution
In a robust scale-out NAS architecture, there is no single master. The metadata is not locked inside one specific controller. Instead, it is distributed evenly across all nodes in the cluster.
Every node in the cluster shares the responsibility of managing file system operations. When a client application sends a request to read or write data, it can often talk to any node in the cluster. Because the metadata is distributed, every node has the intelligence to know where the data resides or how to route the request immediately to the correct location.
This architecture creates a system where the "brain" grows along with the body. If you need more capacity, you add a node. That node brings more storage, but it also brings more CPU and RAM to help manage the file system map. Performance scales linearly with capacity, preventing the bottlenecks common in legacy Network Attached Storage.
How Distribution Eliminates Single Points of Failure
The primary advantage of distributed metadata is resilience. By decoupling the file system management from a specific piece of hardware, the system becomes self-healing and incredibly robust.
1. No Single Point of Failure
If a node in a scale-out cluster fails—perhaps a power supply burns out or a motherboard dies—the system does not crash. Because the metadata and the data are replicated or erasure-coded across the cluster, the remaining nodes instantly pick up the slack.
There is no complex "failover" process where a passive controller has to wake up and mount drives. The other nodes are already active; they simply continue servicing requests using the redundant data copies. To the end-user or application, the failure is often transparent.
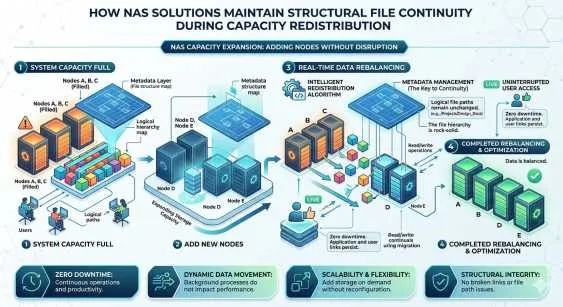
2. Automatic Rebalancing
When a new node is added to the cluster, the system automatically redistributes data and metadata to utilize the new resources. This "rebalancing" happens in the background without downtime.
Conversely, if a drive or node fails, the system identifies the missing data chunks and automatically rebuilds them on the remaining healthy hardware. This self-healing capability ensures that the system returns to a fully protected state without urgent manual intervention from an administrator.
3. Continuous Availability
For mission-critical applications, uptime is non-negotiable. Traditional NAS often requires planned downtime for firmware upgrades or hardware replacements. In a distributed scale-out model, you can take a single node offline for maintenance while the rest of the cluster continues to serve data. You can upgrade an entire cluster, node by node, during business hours with zero interruption to service.
Performance Gains from Parallelism
Beyond reliability, distributing metadata unlocks massive performance gains through parallelism.
In a traditional system, a single file transfer is limited by the bandwidth of the single controller managing that session. In a scale-out environment, large files can be striped across multiple nodes.
When a client requests a large file, multiple nodes can send data chunks simultaneously, saturating the network bandwidth. This is particularly beneficial for high-throughput workflows like video editing, genomic sequencing, or big data analytics. The system isn't just reading from one disk; it's reading from twenty disks across five nodes at the same time.
Is Scale-Out NAS Right for You?
While the benefits are clear, moving to scale-out network attached storage is a strategic decision. It is generally the superior choice for:
- Unstructured Data Growth: If your organization is generating terabytes or petabytes of files (images, videos, logs, documents).
- High-Performance Workflows: Environments that require high throughput and low latency.
- 24/7 Operations: Businesses that cannot afford maintenance windows or downtime.
However, for very small environments with static data needs, a simple scale-up NAS might still suffice. The key is to evaluate not just where your data is today, but where it will be in three years.
The Future of Resilient Storage
The era of the monolithic storage controller is fading. As data becomes the lifeblood of modern enterprise, the risks associated with single points of failure have become too high to accept.
By adopting scale-out NAS with distributed metadata, organizations ensure that their storage infrastructure is resilient, scalable, and ready for whatever comes next. It turns the storage tier from a potential bottleneck into a powerful, flexible asset that drives business continuity.


















Sign in to leave a comment.